UniCharFinder ユニキャラファインダー

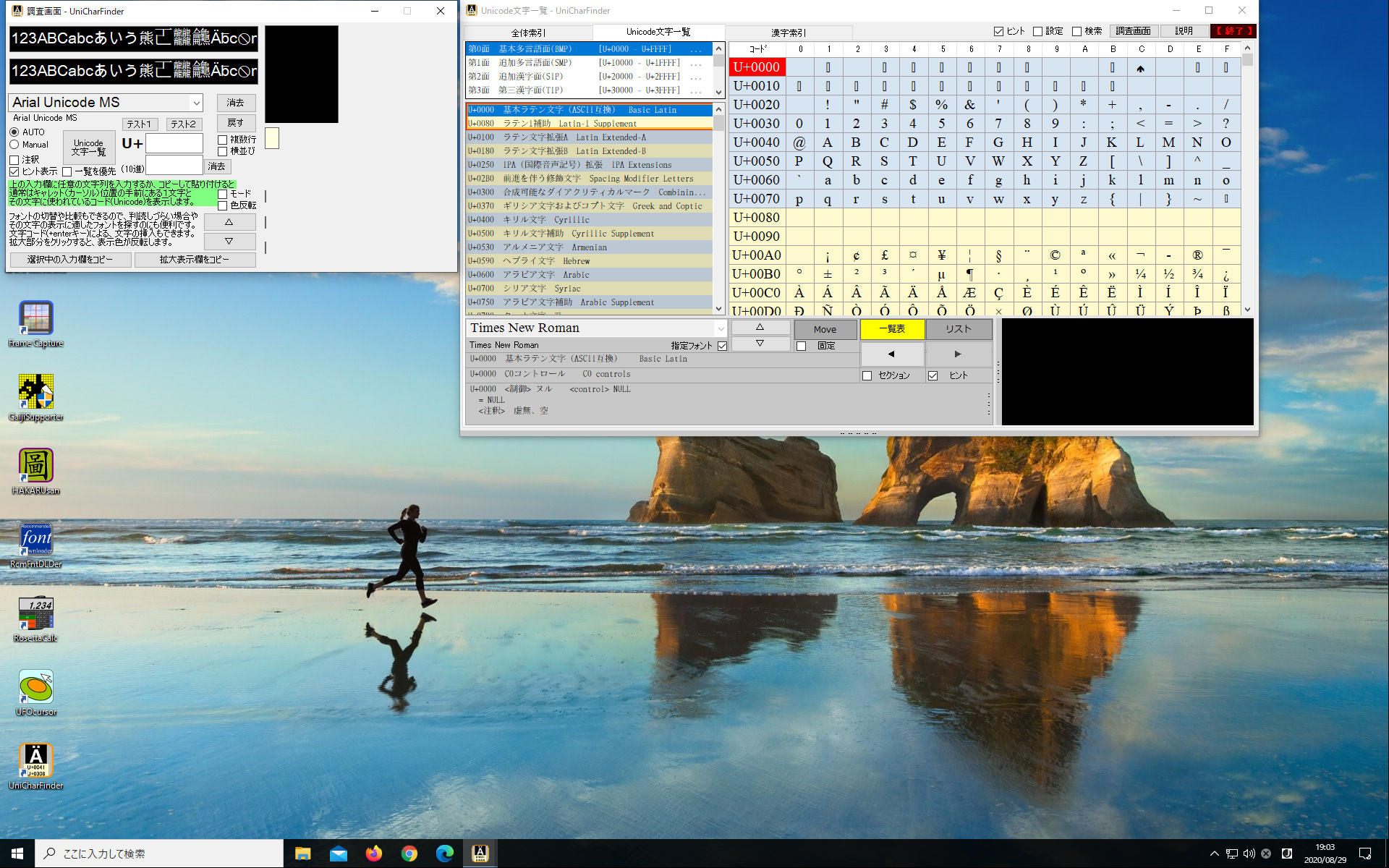
UniCharFinder (ユニキャラファインダー)は
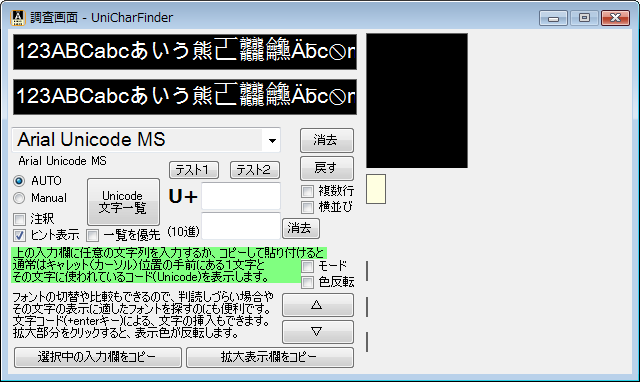
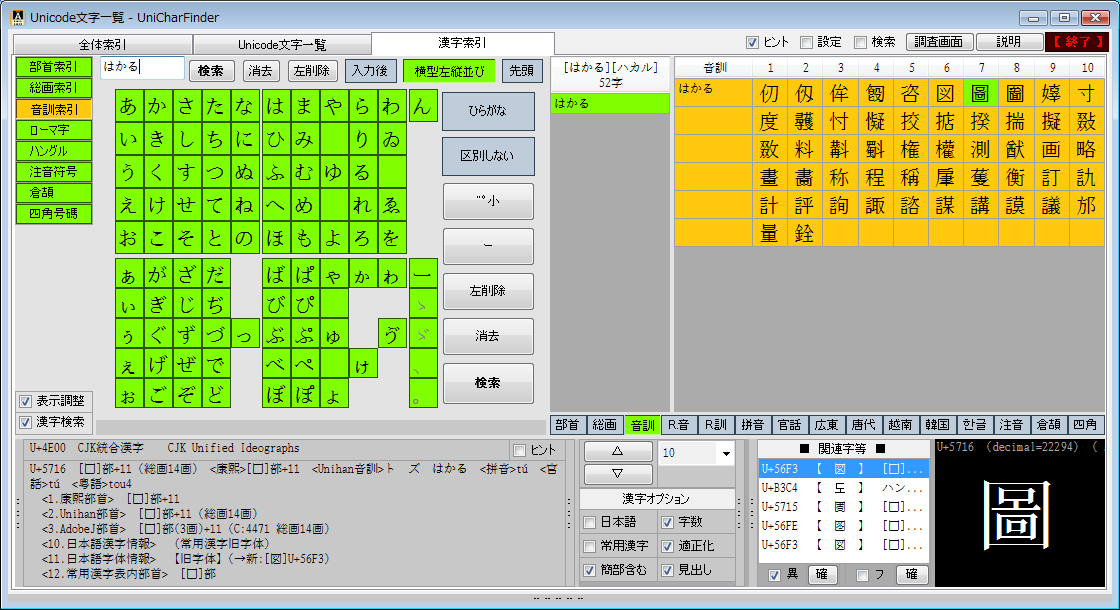
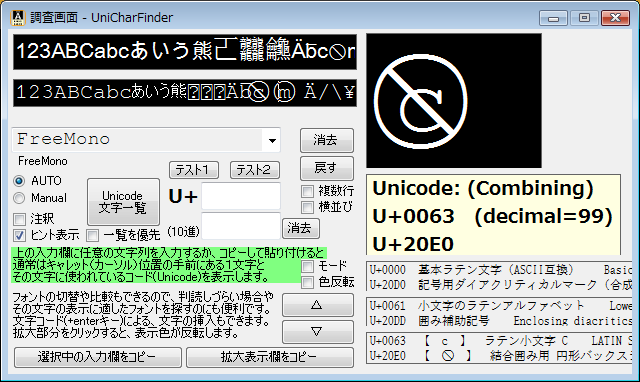
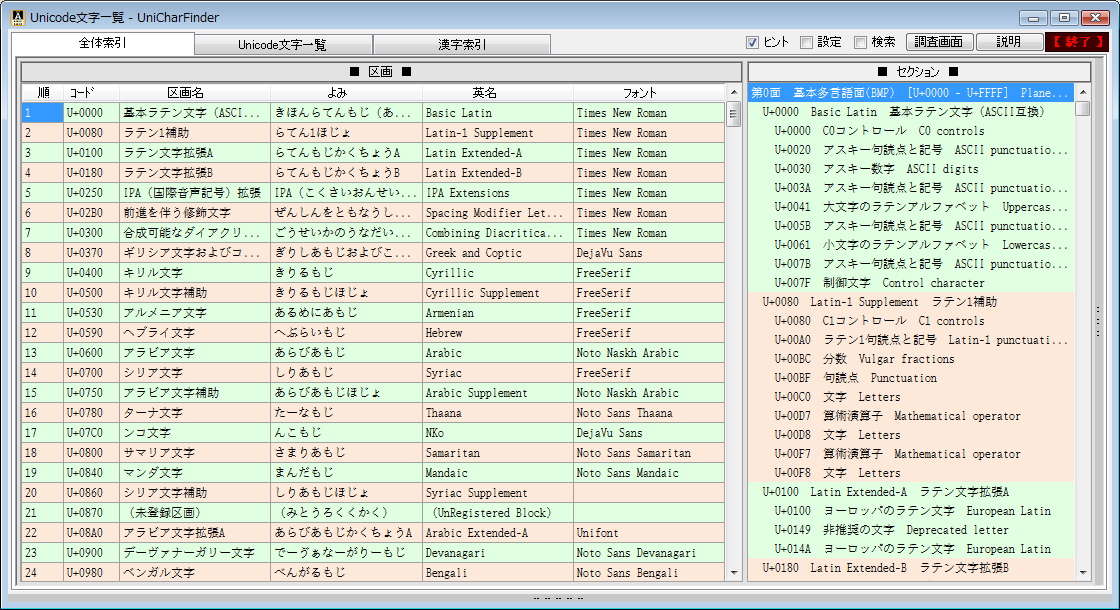
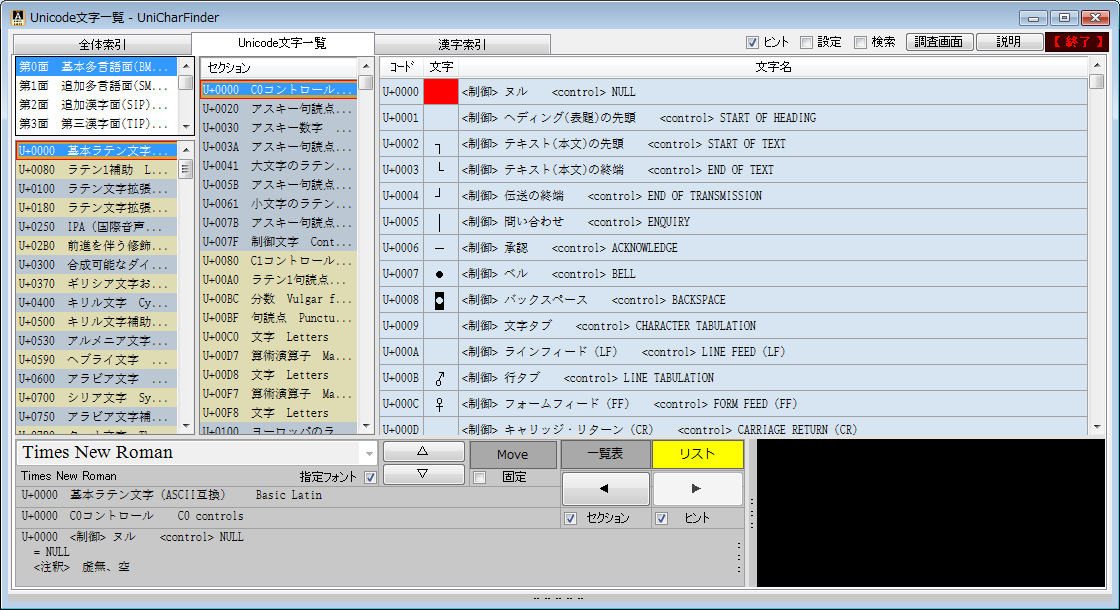
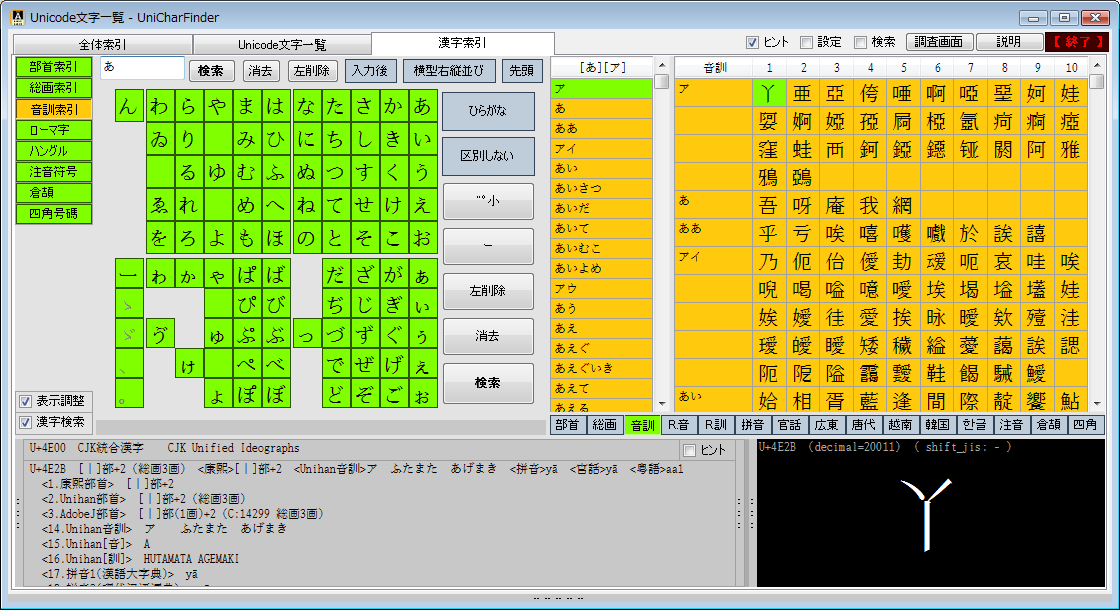
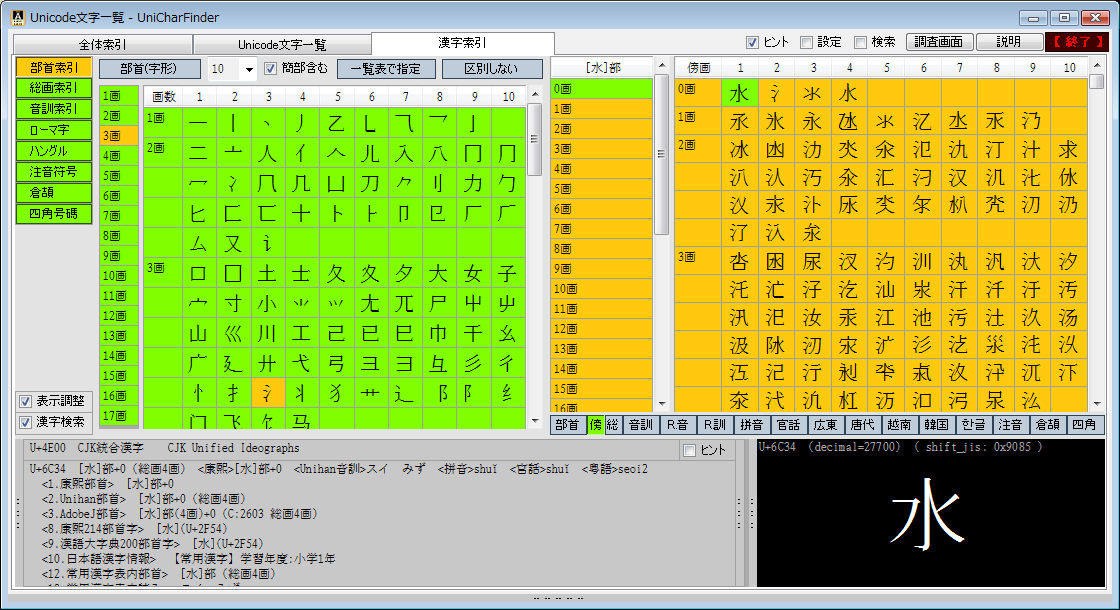
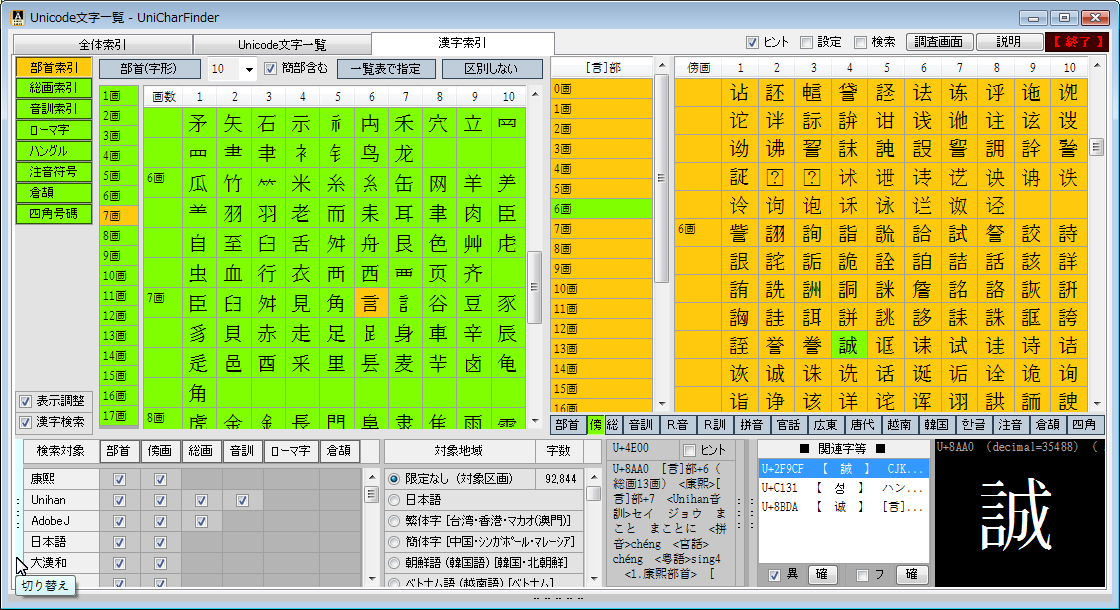
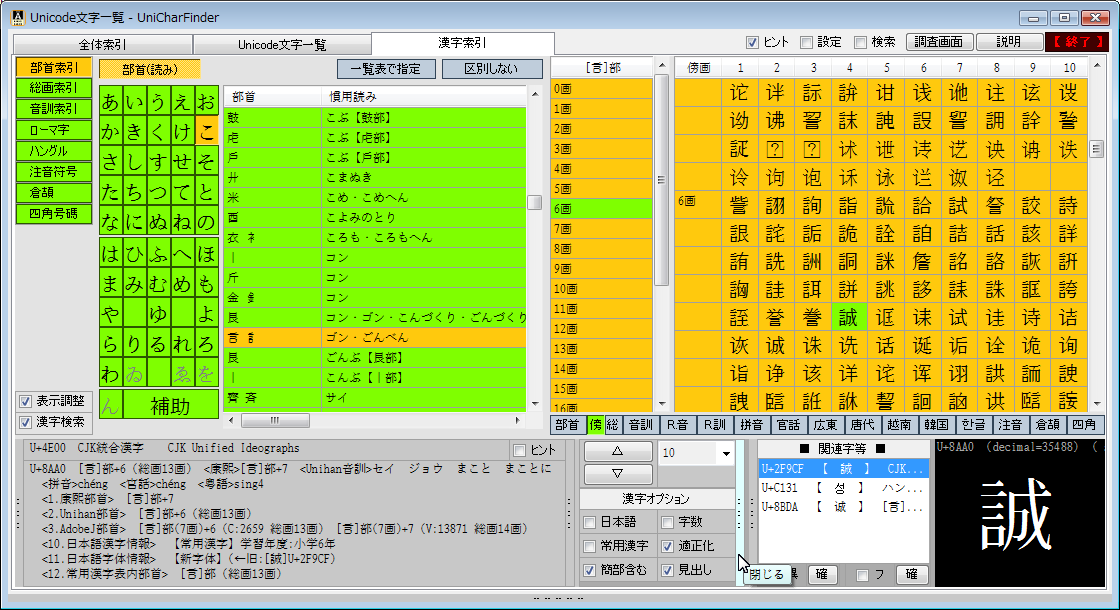
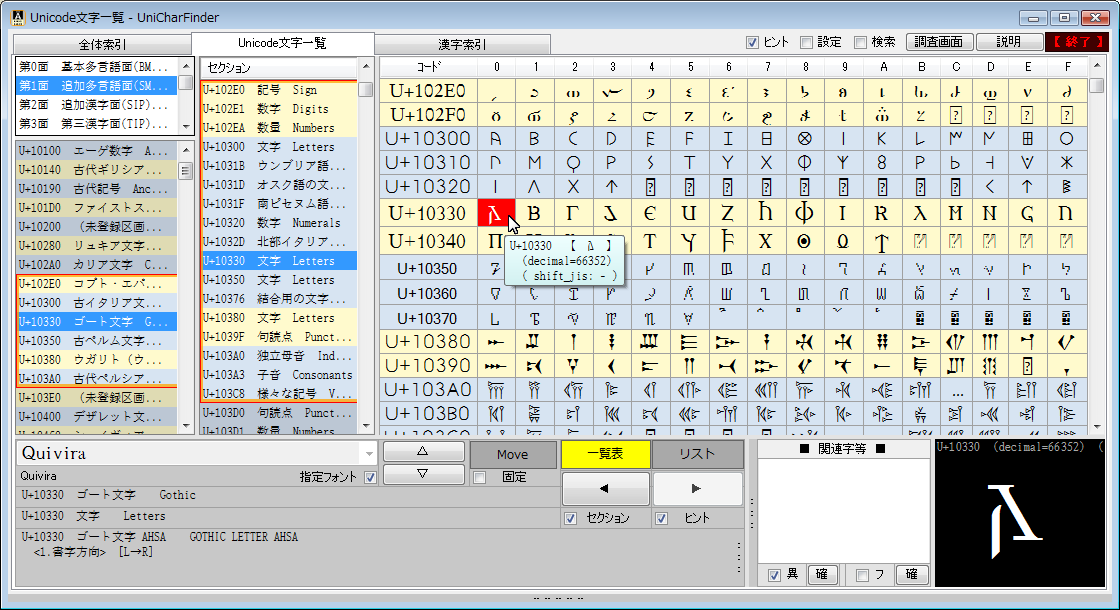
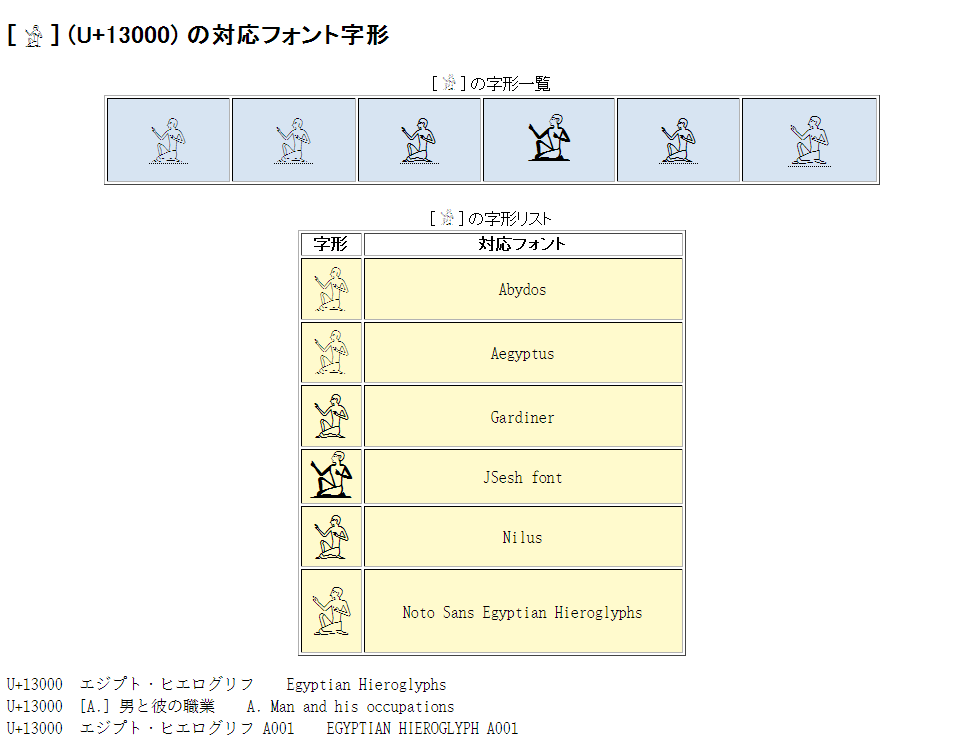
完全な一覧も利用できる Unicode文字の調査・活用向けソフトウェアです。
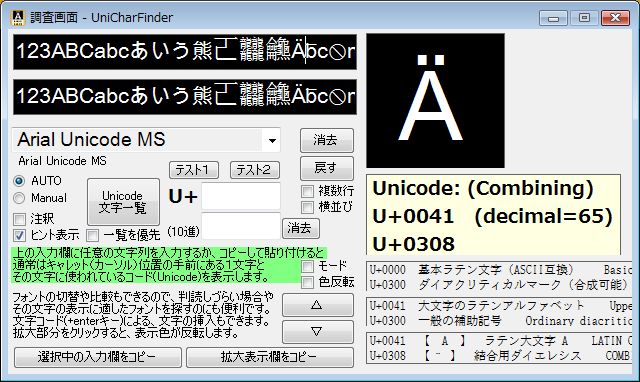
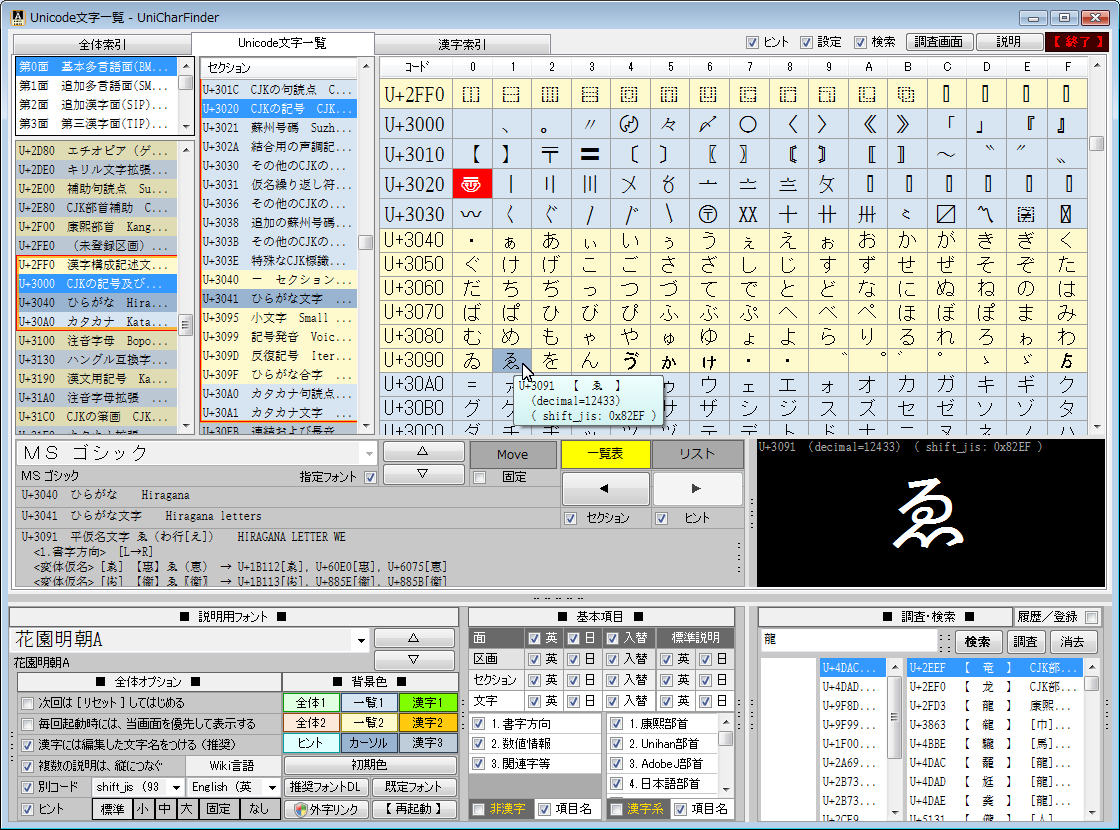
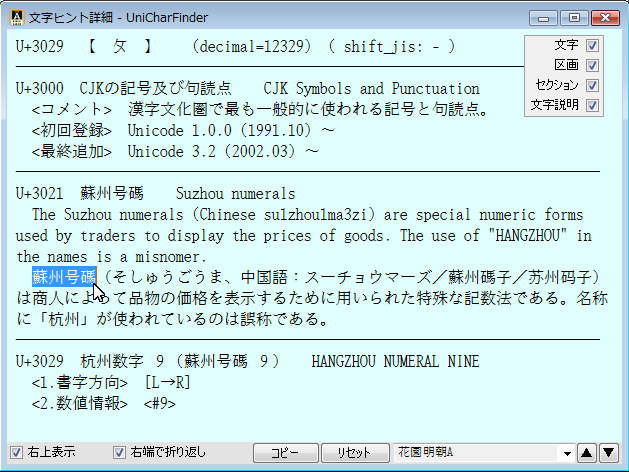
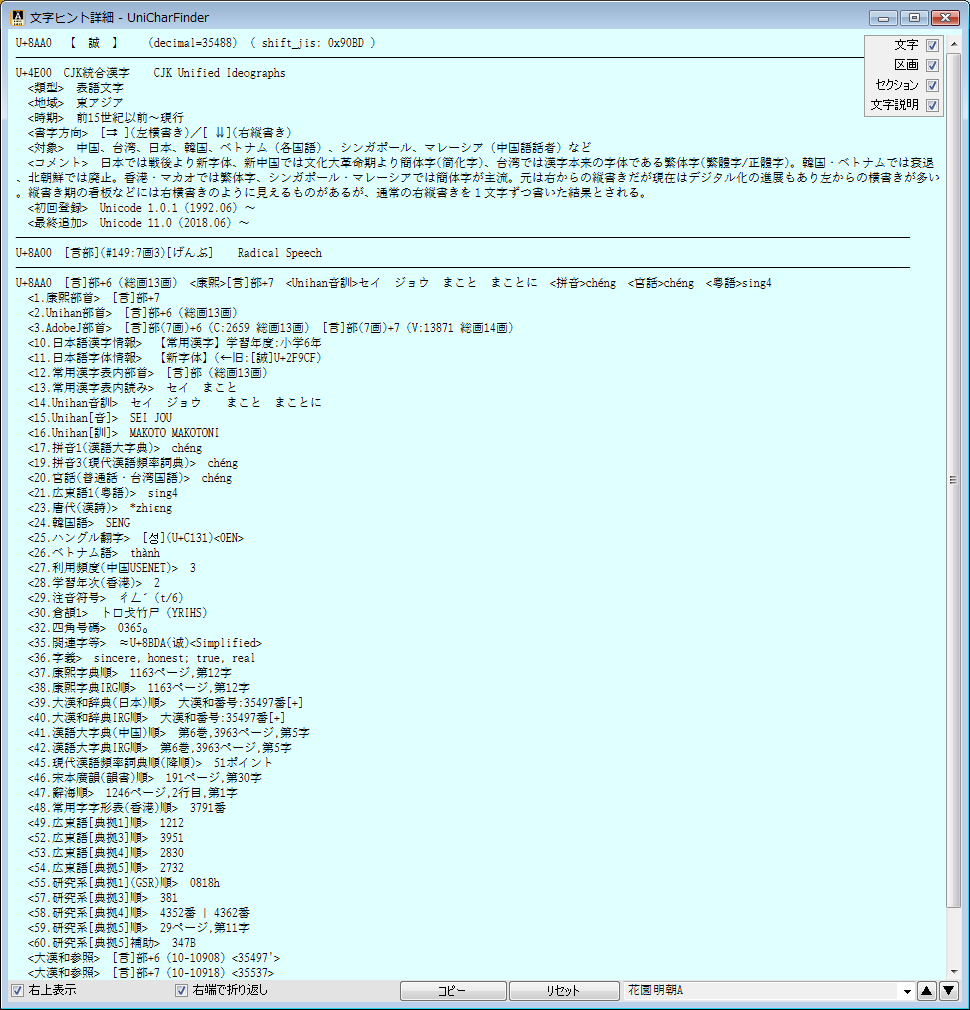
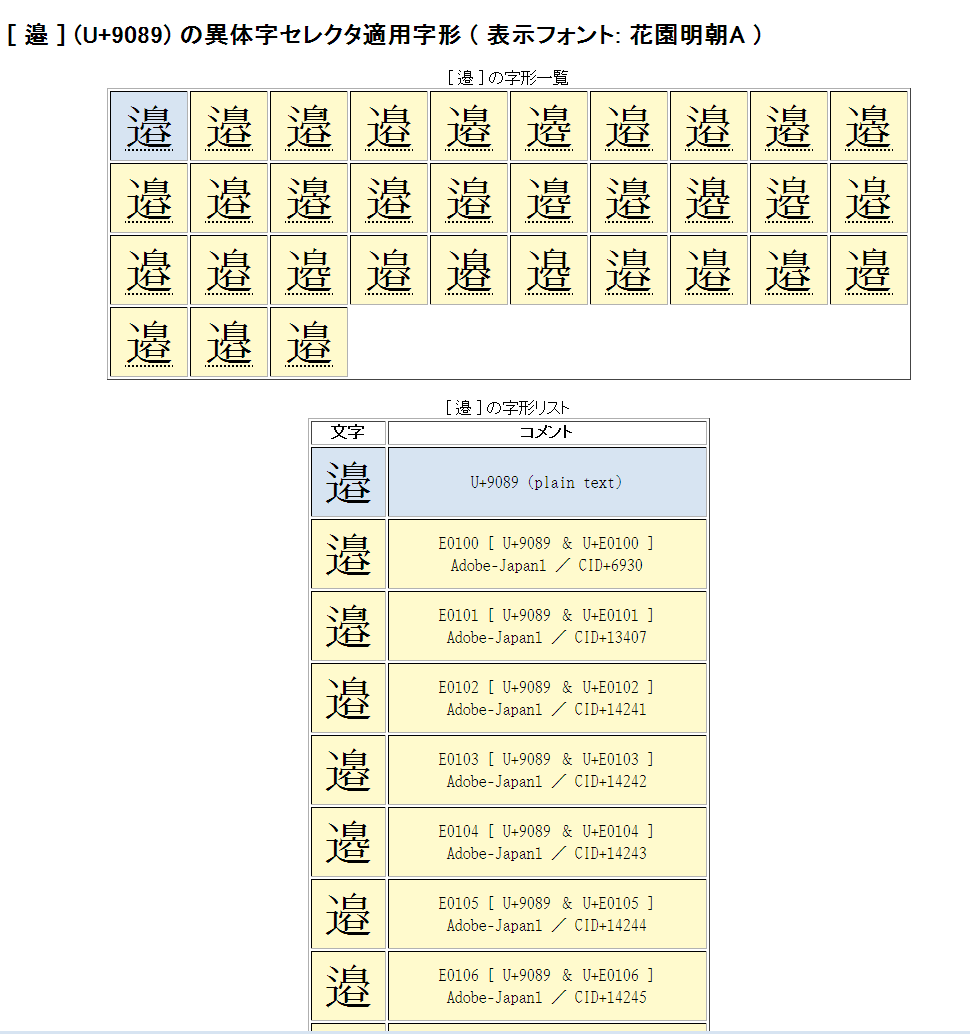
Unicodeに定義される膨大な量の文字を、予定の領域も含めてすべて判別でき 文字の種類ごとに最適なフォントを選択設定し、強力な検索機能やコレクション登録で 外字などの管理や、文字列の要素を分解して結合文字(合字)の成り立ちを調べたり 異体字セレクタ(IVS)を使う際の適切な字形選択への支援などをおこないます。 ※ Unicode 13.0 (2020.03.10 公開) に対応済。 (ver. 1.07)

 インストーラ [ UniCharFinder_Install.exe ] を zip圧縮形式 で ダウンロード
インストーラ [ UniCharFinder_Install.exe ] を zip圧縮形式 で ダウンロード