調査画面
• 文字の調べ方
当アプリを起動すると、インストール直後には、調査画面から起動するようになっています。
 (「一覧を優先」にチェックを入れておくと、次回以降は後述の「Unicode文字一覧」から開くようにもできます。)
まず左上には、黒地に白い文字の入力域が2箇所あります。ここには調査対象の文字列を入力できるようになっており
2行とも「123ABCabcあいう熊𠀀𪚥𪛖Äb̅c⃠…」といった文字列が、初期値として設定されています。
入力欄ですから、調べたい文字列で自由に書き換えできますし、選択中の入力域に対応する「消去」ボタンもあります。
初期値に戻したい場合は「テスト1」ボタンで戻せます。(「テスト2」の文字列は、初期値とは若干異なります。)
内容を変更したあとに、元に戻したい場合は「戻す」ボタンも使えます。(変更が未確定の場合などは戻せない場合があります)
フォント名のコンボボックスは、選択中の入力域のフォントを切り替えます。
入力域が2つあるのは、同じ文字列でも表示フォントを変えることで、見え方に違いが出る場合があるため、その比較用です。
2つとも当初は単一行となっていますが、チェックを入れれば「複数行」入力にも対応します。
文字の大きさは[△][▽]ボタンで調整できます。
ここでは初期値がありますので、ためしに1行目で [→](右矢印キー)を押して、カーソルを1文字分だけ右へ動かしてみます。
(「一覧を優先」にチェックを入れておくと、次回以降は後述の「Unicode文字一覧」から開くようにもできます。)
まず左上には、黒地に白い文字の入力域が2箇所あります。ここには調査対象の文字列を入力できるようになっており
2行とも「123ABCabcあいう熊𠀀𪚥𪛖Äb̅c⃠…」といった文字列が、初期値として設定されています。
入力欄ですから、調べたい文字列で自由に書き換えできますし、選択中の入力域に対応する「消去」ボタンもあります。
初期値に戻したい場合は「テスト1」ボタンで戻せます。(「テスト2」の文字列は、初期値とは若干異なります。)
内容を変更したあとに、元に戻したい場合は「戻す」ボタンも使えます。(変更が未確定の場合などは戻せない場合があります)
フォント名のコンボボックスは、選択中の入力域のフォントを切り替えます。
入力域が2つあるのは、同じ文字列でも表示フォントを変えることで、見え方に違いが出る場合があるため、その比較用です。
2つとも当初は単一行となっていますが、チェックを入れれば「複数行」入力にも対応します。
文字の大きさは[△][▽]ボタンで調整できます。
ここでは初期値がありますので、ためしに1行目で [→](右矢印キー)を押して、カーソルを1文字分だけ右へ動かしてみます。
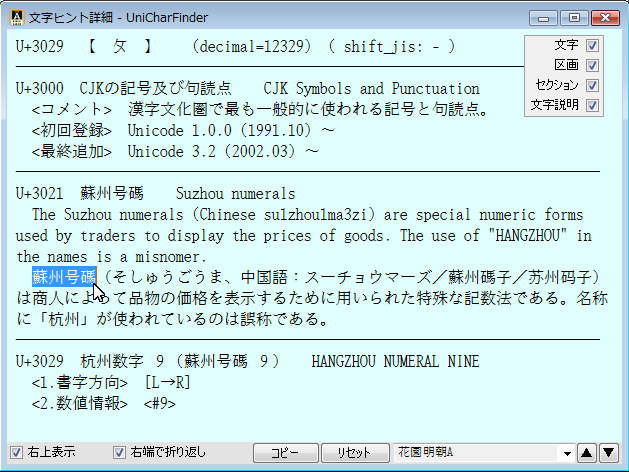
 画面右側に、いまカーソルが動いた箇所の文字が拡大表示され、その文字 [1] についての調査結果が表示されました。
調査結果の各欄の内容は、右クリックからコピーできます。再録すると、次のようになっていました。
• 黄色地に太字の部分
Unicode: (single)
U+0031 (decimal=49)
( shift_jis: 0x31 )
この部分では、まず1行目「Unicode:」の次の「(single)」は
調査対象の [1] が、単独の文字であることを示しています。(その他の場合については後述)
2行目「U+0031 (decimal=49)」は、調査対象の [1] の、Unicode における文字コード(コードポイント)です。
Unicode には16進コードと10進コードの2種類の表記法があります。
16進の場合は先頭に [U+] を付ける明確化が広くおこなわれます。10進は、ここでは [decimal=] で示しています。
これは [n進法] を数学的に変換するだけです。(0000₍₁₆₎ = 0₍₁₀₎)(0020₍₁₆₎ = 32₍₁₀₎)(0031₍₁₆₎ = 49₍₁₀₎)
3行目は、書いてあるとおり、shift_jis でのコードポイントです。
Unicode は、以前から利用されてきた(shift_jis,ASCII,GB,Big5等を含む)すべての文字コード(符号化文字集合)を
統合するものです。このため、文字によっては shift_jis でのコードポイントが付けられていない場合もあります。
• 灰色地に個別に枠線囲みの部分
U+0000 基本ラテン文字(ASCII互換) Basic Latin
U+0030 アスキー数字 ASCII digits
U+0031 【 1 】 数字 1 DIGIT ONE
この部分は、上から順に、Unicode の「区画」「セクション」「文字」についての情報です。
「区画」は、Unicode の [Block] のことで、各言語ごとなどで区分けされた「文字種」といえます。
各種フォントも、この区画ごとに、対応/非対応が分かれるものが多くなっています。
「セクション」は、Unicode の各区画ごとのコード表の中を、用途などで区切る「サブ文字種」ともいえるものです。
重要度は必ずしも高くありませんが、各文字に対する前提的な説明としても利用できる、有意義なものです。
「文字」は、前述の「U+0031」の16進コードからもわかるように、当然ながら「文字そのもの」をあらわします。
Unicode では「文字名」が付けられていることが多いため、その情報が表示されます。(漢字など一部の文字種を除く)
では次に、すこしだけ [→](右矢印キー)を[長押し]して、数文字分だけカーソルを進めてみます。
画面右側に、いまカーソルが動いた箇所の文字が拡大表示され、その文字 [1] についての調査結果が表示されました。
調査結果の各欄の内容は、右クリックからコピーできます。再録すると、次のようになっていました。
• 黄色地に太字の部分
Unicode: (single)
U+0031 (decimal=49)
( shift_jis: 0x31 )
この部分では、まず1行目「Unicode:」の次の「(single)」は
調査対象の [1] が、単独の文字であることを示しています。(その他の場合については後述)
2行目「U+0031 (decimal=49)」は、調査対象の [1] の、Unicode における文字コード(コードポイント)です。
Unicode には16進コードと10進コードの2種類の表記法があります。
16進の場合は先頭に [U+] を付ける明確化が広くおこなわれます。10進は、ここでは [decimal=] で示しています。
これは [n進法] を数学的に変換するだけです。(0000₍₁₆₎ = 0₍₁₀₎)(0020₍₁₆₎ = 32₍₁₀₎)(0031₍₁₆₎ = 49₍₁₀₎)
3行目は、書いてあるとおり、shift_jis でのコードポイントです。
Unicode は、以前から利用されてきた(shift_jis,ASCII,GB,Big5等を含む)すべての文字コード(符号化文字集合)を
統合するものです。このため、文字によっては shift_jis でのコードポイントが付けられていない場合もあります。
• 灰色地に個別に枠線囲みの部分
U+0000 基本ラテン文字(ASCII互換) Basic Latin
U+0030 アスキー数字 ASCII digits
U+0031 【 1 】 数字 1 DIGIT ONE
この部分は、上から順に、Unicode の「区画」「セクション」「文字」についての情報です。
「区画」は、Unicode の [Block] のことで、各言語ごとなどで区分けされた「文字種」といえます。
各種フォントも、この区画ごとに、対応/非対応が分かれるものが多くなっています。
「セクション」は、Unicode の各区画ごとのコード表の中を、用途などで区切る「サブ文字種」ともいえるものです。
重要度は必ずしも高くありませんが、各文字に対する前提的な説明としても利用できる、有意義なものです。
「文字」は、前述の「U+0031」の16進コードからもわかるように、当然ながら「文字そのもの」をあらわします。
Unicode では「文字名」が付けられていることが多いため、その情報が表示されます。(漢字など一部の文字種を除く)
では次に、すこしだけ [→](右矢印キー)を[長押し]して、数文字分だけカーソルを進めてみます。
 調査結果が「その文字数ぶん」に変わりました。
黄色地の部分の「Mixture」は「混合」という意味で、調査結果が数文字分あることを示しています。
また先頭の文字 [2] については [decimal=] の明記がありますが、後続の文字はまとめて順に書かれています。
灰色地の部分は、複数の文字について書かれているので、すべては見えていません。
次の画像は、見えない部分ができたので、画面の枠を拡げているところです。
調査結果が「その文字数ぶん」に変わりました。
黄色地の部分の「Mixture」は「混合」という意味で、調査結果が数文字分あることを示しています。
また先頭の文字 [2] については [decimal=] の明記がありますが、後続の文字はまとめて順に書かれています。
灰色地の部分は、複数の文字について書かれているので、すべては見えていません。
次の画像は、見えない部分ができたので、画面の枠を拡げているところです。
 各領域には分割線がありますので、個々の文字が属するセクションや区画を確認したい場合は ドラッグ操作で領域を拡げて下さい。
各領域には分割線がありますので、個々の文字が属するセクションや区画を確認したい場合は ドラッグ操作で領域を拡げて下さい。

 (次の画像は少し縮小しています。)
(次の画像は少し縮小しています。)
 または「横並び」にチェックを入れると、次のようにもできます。
または「横並び」にチェックを入れると、次のようにもできます。
 次の画像では「注釈」にチェックを入れて、先頭の[1]を調べなおしています。
次の画像では「注釈」にチェックを入れて、先頭の[1]を調べなおしています。
 区画名や文字名だけでなく、区画や文字にまつわる注釈が、追加的に表示されています。
(広い面積が必要なため画像にしていませんが、文字が複数の場合でも注釈の表示は可能です。)
これらの情報は、当アプリが Unicodeで定義されたすべての文字をカバーしているために実現できていることであり
「Unicode文字一覧」ボタンから、個々の文字について確認することもできます。(後述)
区画名や文字名だけでなく、区画や文字にまつわる注釈が、追加的に表示されています。
(広い面積が必要なため画像にしていませんが、文字が複数の場合でも注釈の表示は可能です。)
これらの情報は、当アプリが Unicodeで定義されたすべての文字をカバーしているために実現できていることであり
「Unicode文字一覧」ボタンから、個々の文字について確認することもできます。(後述)
• サロゲートペアの調査
カーソルを進めますと、漢字については、Unicodeで用意される「文字名」がありません。
このため、漢字についての「文字」の欄には、その漢字に関する、部首や画数などの情報が表示されます。
 (漢字については、Unicode側の「セクション」もありませんので、当方で便宜的に付けたものが表示されます。)
初期値の文字列は「123ABCabcあいう熊」までの先頭部分が Unicode第0面「基本多言語面」の文字です。
基本多言語面のコードポイントは、16進で4桁まで(0000₍₁₆₎ = 0₍₁₀₎)~(FFFF₍₁₆₎ = 65535₍₁₀₎)の範囲となっています。
Unicode第1面「追加多言語面」は、16進で5桁の(10000₍₁₆₎ = 65536₍₁₀₎)~(1FFFF₍₁₆₎ = 131071₍₁₀₎)ですが
初期値の文字列の「123ABCabcあいう熊」に続く、日本語ではあまり使われない3文字「𠀀𪚥𪛖」は
Unicode第2面「追加漢字面」の文字であるため(20000₍₁₆₎ = 131072₍₁₀₎)~(2FFFF₍₁₆₎ = 196607₍₁₀₎)の範囲です。
ちなみに
U+20000「𠀀」は、追加漢字面の先頭区画「CJK統合漢字拡張B」の、先頭の文字
U+2A6A5「𪚥」は、Unicode 12.1 までの最多画数であった、64画の漢字のひとつ([龍]が4つ)
U+2A6D6「𪛖」は、追加漢字面の先頭区画「CJK統合漢字拡張B」の、最後の文字
を掲載しています。(Unicode第2面「追加漢字面」には「CJK統合漢字拡張C,D,E,F」などもあります。)
(Unicode 13.0 で 第3面「第三漢字面」に「CJK統合漢字拡張G」が追加されたため、画数最多は 84画の U+3106C [𱁬](たいと,だいと,おとど) です。)
これら第1面以降はすべて「サロゲート・ペア」(surrogate pair:代用対:だいようつい)の文字となっています。
サロゲートペアは「上位代用符号位置」と「下位代用符号位置」(第0面の区画でともに1024文字)に属する2文字を
ペアとして組み合わせて使うことで、代用的に、第1面以降の1文字を構成するものです。
表示に用いるフォントによっては、第0面の文字の多くには対応していても、第1面以降には対応していない場合があります。
第1面以降の文字数は、組み合わせの総数で 1024×1024=1,048,576文字 となります。16面で分けると各面 65,536文字で
第0面の 65,536文字とあわせると、Unicodeの仕組みとして確保可能な総文字数は、全17面分の 1,114,112文字 となります。
(「上位」先頭の 64文字 ×「下位」1,024文字 = 第1面 65,536文字
「上位」 次の 64文字 ×「下位」1,024文字 = 第2面 65,536文字、、、のように続きます。)
(ただし総文字数 1,114,112文字 というのは理論値で、具体的に使えるのは
第0面の上下「代用符号位置」2,048文字が第1面以降に使われる重複を省いた 1,112,064文字です。
さらに、Unicodeコンソーシアムにより文字としての使用を禁止されているコードポイントや
確保済みの区画内には将来も文字が埋まらないコードポイントもあるので、実際はもっと少なくなります。)
当画面左端のラジオボタンを「AUTO」から「Manual」に切り替えて、前出の漢字を含む部分をもう一度調べると
サロゲートペアの各文字を構成する、第0面の上下「代用符号位置」で表現されるコードポイントもわかります。
(漢字については、Unicode側の「セクション」もありませんので、当方で便宜的に付けたものが表示されます。)
初期値の文字列は「123ABCabcあいう熊」までの先頭部分が Unicode第0面「基本多言語面」の文字です。
基本多言語面のコードポイントは、16進で4桁まで(0000₍₁₆₎ = 0₍₁₀₎)~(FFFF₍₁₆₎ = 65535₍₁₀₎)の範囲となっています。
Unicode第1面「追加多言語面」は、16進で5桁の(10000₍₁₆₎ = 65536₍₁₀₎)~(1FFFF₍₁₆₎ = 131071₍₁₀₎)ですが
初期値の文字列の「123ABCabcあいう熊」に続く、日本語ではあまり使われない3文字「𠀀𪚥𪛖」は
Unicode第2面「追加漢字面」の文字であるため(20000₍₁₆₎ = 131072₍₁₀₎)~(2FFFF₍₁₆₎ = 196607₍₁₀₎)の範囲です。
ちなみに
U+20000「𠀀」は、追加漢字面の先頭区画「CJK統合漢字拡張B」の、先頭の文字
U+2A6A5「𪚥」は、Unicode 12.1 までの最多画数であった、64画の漢字のひとつ([龍]が4つ)
U+2A6D6「𪛖」は、追加漢字面の先頭区画「CJK統合漢字拡張B」の、最後の文字
を掲載しています。(Unicode第2面「追加漢字面」には「CJK統合漢字拡張C,D,E,F」などもあります。)
(Unicode 13.0 で 第3面「第三漢字面」に「CJK統合漢字拡張G」が追加されたため、画数最多は 84画の U+3106C [𱁬](たいと,だいと,おとど) です。)
これら第1面以降はすべて「サロゲート・ペア」(surrogate pair:代用対:だいようつい)の文字となっています。
サロゲートペアは「上位代用符号位置」と「下位代用符号位置」(第0面の区画でともに1024文字)に属する2文字を
ペアとして組み合わせて使うことで、代用的に、第1面以降の1文字を構成するものです。
表示に用いるフォントによっては、第0面の文字の多くには対応していても、第1面以降には対応していない場合があります。
第1面以降の文字数は、組み合わせの総数で 1024×1024=1,048,576文字 となります。16面で分けると各面 65,536文字で
第0面の 65,536文字とあわせると、Unicodeの仕組みとして確保可能な総文字数は、全17面分の 1,114,112文字 となります。
(「上位」先頭の 64文字 ×「下位」1,024文字 = 第1面 65,536文字
「上位」 次の 64文字 ×「下位」1,024文字 = 第2面 65,536文字、、、のように続きます。)
(ただし総文字数 1,114,112文字 というのは理論値で、具体的に使えるのは
第0面の上下「代用符号位置」2,048文字が第1面以降に使われる重複を省いた 1,112,064文字です。
さらに、Unicodeコンソーシアムにより文字としての使用を禁止されているコードポイントや
確保済みの区画内には将来も文字が埋まらないコードポイントもあるので、実際はもっと少なくなります。)
当画面左端のラジオボタンを「AUTO」から「Manual」に切り替えて、前出の漢字を含む部分をもう一度調べると
サロゲートペアの各文字を構成する、第0面の上下「代用符号位置」で表現されるコードポイントもわかります。
 「𠀀𪚥𪛖」の3文字は、「上位」と「下位」の2文字ずつのペア計6文字から構成されていることがわかります。
もちろん、すべての文字は1文字ずつで調べることもできます。以下は [AUTO] の場合と [Manual] の場合です。
「𠀀𪚥𪛖」の3文字は、「上位」と「下位」の2文字ずつのペア計6文字から構成されていることがわかります。
もちろん、すべての文字は1文字ずつで調べることもできます。以下は [AUTO] の場合と [Manual] の場合です。





 サロゲートペアの1文字ずつのため、[AUTO] では黄色地の表示が (Surrogate Pair) となっており
黄色地の3行目には「代用符号位置」を上位と下位に分解したコードまで表示されています。
ちなみに、この「上位」と「下位」の文字のペアを、「メモ帳」などを使って同じ順番で並べると
表示フォントさえ対応していれば、サロゲートペアの1文字ずつを「再構成」することもできます。
サロゲートペアの1文字ずつのため、[AUTO] では黄色地の表示が (Surrogate Pair) となっており
黄色地の3行目には「代用符号位置」を上位と下位に分解したコードまで表示されています。
ちなみに、この「上位」と「下位」の文字のペアを、「メモ帳」などを使って同じ順番で並べると
表示フォントさえ対応していれば、サロゲートペアの1文字ずつを「再構成」することもできます。
• 最適なフォントを探す
カーソルをさらに進めますと、「Äb̅c⃠m⃝Ä」のあたりは「フォント」や「結合文字」についての確認用文字列です。
結合用記号は、多くの場合、ラテン文字系の分音記号(分音符、ダイアクリティカルマーク)を指します。
 最初の「Ä」と最後の「Ä」は、同じように見えますが、実際は違う文字であることに注意してください。
最初の「Ä」と最後の「Ä」は、同じように見えますが、実際は違う文字であることに注意してください。
最初の「Ä」は、いわゆる「普通のA」の直後に、結合用記号を配した、2文字からなる「結合文字」です。
(この結合文字([U+0041]&[U+0308])は、当アプリを象徴するアイコンとしても利用しています。)→ |  |
最後の「Ä」は、単独の「合成済み文字」とも呼ばれるもので、「普通のA」とは異なる文字です。
(なお、画像にはありませんが「普通のA」の直後に結合用でない[¨](U+00A8)を付けても[A¨]となるだけです。) |
日本語でいえば、濁点つきの平仮名「だ」は「合成済み文字」ですが
濁点なしの「た」の直後に結合用濁点「゙」(U+3099)を配した「だ」は、1文字分の幅となる「結合文字」です。
(もちろん「た」の直後に結合用でない濁点「゛」(U+309B)を付けても、2文字分の幅で「た゛」になるだけです。)
(日本語IMEの[かな入力]では、「た」の直後に濁点「゛」を打てば、一瞬で「だ」に置き換えられています。)
ラテン文字のダイアクリティカルマークは、中国語の拼音(ピンイン)や、ベトナム語(クォック・グー)などでも多用されますし
日本語ローマ字でも「おう」「おお」の表記に、[Ō/ō](旧ヘボン式) や [Ô/ô](訓令式) を使う場合などがあります。
画像の文字列では、最初の「
Ä」と最後の「
Ä」のあいだの文字にも結合用記号が使われていますが
これらのうち「
Äb̅」までは「文字用」の結合記号で、「
c⃠m⃝」に使っているのは「記号用」の結合記号です。
画像で選択しているフォント「Arial Unicode MS」では、「記号用」については正しく結合できていないのもわかります。
(当ページの基本フォントはメイリオにしていますが、お使いのWEBブラウザやフォントではどうでしょうか?)
フォント名のコンボボックスは、クリックして開くフォント名のリストから選ぶこともできますが
マウスのポインタ矢印を重ねていれば、キーボードの上下矢印キーで、簡単・高速に切り替えることもできます。

この機能を使うと、表示フォントを高速に切り替えて、文字列に対応した最適なフォントを選びやすくできます。
フォントの切替は、選択したほうの入力域だけが対象になるので、もう一方の入力域のフォントはそのままです。
このことを利用して、対応フォントを比較するのにも使えます。
たとえば日本語用のフォントでは、ラテン文字などを使う言語で多用される 結合記号 に対応するものは少ないようです。

ちょっと脱線しますが、メイリオの場合は「バックスラッシュ」(リバースソリダス。逆向きの[/]。[\]←これは全角)が
「円記号」([¥]。[¥]←これは全角)の字形になっていることもわかります。(
バックスラッシュ問題)
少なくとも Vista版のメイリオは 結合記号に対応していないようだということもわかりますね。

花園明朝Aの場合は、最初の「
Ä」と最後の「
Ä」の字形が違ってしまっています。
本来だと同じ字形にならないといけないはずですが、考えようによっては、かえって親切なようにも思えます。
欧文ラテン文字系のフォントでは、文字用の結合記号には多くが対応しますが
記号用の結合記号にまで対応するものは、比較的限られるようです。
(以下は当方の手持ちフォントの中で記号用の結合記号にも対応しているものたちです。)





この他、初期値の文字列には様々な文字種を入れていますので
カーソルを動かしたりフォントを変えたりしてお試しください。
• 任意の文字列を調べる
当アプリでは、調べたい文字列そのものを、入力欄へ「貼り付け」すれば、簡単に調べることができます。
たとえば、日本語版ウィキペディアで[ 日本の文化 ]というページを開き
そのページの左側にある「他言語版」から[ العربية ](アラビア語)」や[ हिन्दी ](ヒンディー語)のページを開いてみると
アラビア文字やデーヴァナーガリーで書かれた「日本の文化」についてのページが表示されます。
これらの文字は「続け書きによる字形変化」を伴う文字としても知られます。
ここでは、それらのページでタイトルとなっている箇所の文字列をコピーし
当アプリの入力域を消去した上で貼り付けて、どのような文字が使われているか、調べてみました。
 (アラビア文字の書字方向は[左←右]です。
入力域は「右詰め」になっていませんが、調査結果は「右から順」になっています。)
(アラビア文字の書字方向は[左←右]です。
入力域は「右詰め」になっていませんが、調査結果は「右から順」になっています。)
 (多言語国家インドの公用語ヒンディー語は、デーヴァナーガリーで書かれます。書字方向は[左→右]です。)
対象の文字列が複数行におよぶ場合は、先に「複数行」にチェックを入れてから貼り付けるようにしてください。
このように、あまり使い慣れない言語の、複雑な字形変化を伴う文字でも
文や単語に使われている文字の構成を調べることで、理解の一助にすることができます。
なお、この機能は「Unicode文字一覧」の「検索」画面でも、「調査」として、同様におこなうことができます。(後述)
(多言語国家インドの公用語ヒンディー語は、デーヴァナーガリーで書かれます。書字方向は[左→右]です。)
対象の文字列が複数行におよぶ場合は、先に「複数行」にチェックを入れてから貼り付けるようにしてください。
このように、あまり使い慣れない言語の、複雑な字形変化を伴う文字でも
文や単語に使われている文字の構成を調べることで、理解の一助にすることができます。
なお、この機能は「Unicode文字一覧」の「検索」画面でも、「調査」として、同様におこなうことができます。(後述)
• その他の機能
調べたい文字について、文字コード(コードポイント)が事前にわかっている場合は
16進または10進のコードを指定すれば、選択中の入力域にその文字が挿入されますので、これによって調べることも可能です。
ためしに例として、画面中央の[U+]の欄に、適当に[1234]や[12345]と入力してみます。
 →
→  ([U+]の隣に[1234]と入力。16進の[U+1234]なので、リターンキーを押すと、該当する「エチオピア文字」が表示されます。
エチオピア文字はゲエズ文字ともいい、アフリカ東部エチオピアの公用語アムハラ語で使われている文字です。
基本的に現行言語の文字の多くは16進4桁の「基本多言語面」に属し、多くのフォントが対応しています。
なお、10進コードで指定する場合は、[U+]の下側の入力欄に、アラビア数字だけで入力します。)
([U+]の隣に[1234]と入力。16進の[U+1234]なので、リターンキーを押すと、該当する「エチオピア文字」が表示されます。
エチオピア文字はゲエズ文字ともいい、アフリカ東部エチオピアの公用語アムハラ語で使われている文字です。
基本的に現行言語の文字の多くは16進4桁の「基本多言語面」に属し、多くのフォントが対応しています。
なお、10進コードで指定する場合は、[U+]の下側の入力欄に、アラビア数字だけで入力します。)
 →
→  (さらに続けて[12345]と入力。16進の[U+12345]なので「楔形文字」のため、右画像では表示フォントを切り替えています。
現行の言語でない古代の文字などは「追加多言語面」に属し、その多くは特定のフォントでなければ表示できません。
サロゲートペアの1文字分なので、黄色地の欄は (Surrogate Pair) の表示となっています。)
ほかに当画面の機能としては、「モード」と「色反転」のチェックボックスがあります。
(さらに続けて[12345]と入力。16進の[U+12345]なので「楔形文字」のため、右画像では表示フォントを切り替えています。
現行の言語でない古代の文字などは「追加多言語面」に属し、その多くは特定のフォントでなければ表示できません。
サロゲートペアの1文字分なので、黄色地の欄は (Surrogate Pair) の表示となっています。)
ほかに当画面の機能としては、「モード」と「色反転」のチェックボックスがあります。

 「モード」は、拡大表示域の表示モードを、[テキストモード]から[グラフィクスモード]へ切り替えるものです。
わかりやすくするため、文字の色を緑色にし、文字に対するベースラインや上下左右の幅も計測して表示します。
([テキストモード]と[グラフィクスモード]の表示位置は、若干ズレています。)
「色反転」は、2つの入力域と拡大表示域の3箇所で、[文字色]と[背景色]とを単純に入れ替えるものです。
「メモ帳」などの一般的な白地の環境で、どう見えるか、簡単に試すことができます。
これらについては、次項「Unicode文字一覧」でも利用可能です。
「モード」は、拡大表示域の表示モードを、[テキストモード]から[グラフィクスモード]へ切り替えるものです。
わかりやすくするため、文字の色を緑色にし、文字に対するベースラインや上下左右の幅も計測して表示します。
([テキストモード]と[グラフィクスモード]の表示位置は、若干ズレています。)
「色反転」は、2つの入力域と拡大表示域の3箇所で、[文字色]と[背景色]とを単純に入れ替えるものです。
「メモ帳」などの一般的な白地の環境で、どう見えるか、簡単に試すことができます。
これらについては、次項「Unicode文字一覧」でも利用可能です。
Unicode文字一覧
• Unicode文字一覧
調査画面で「Unicode文字一覧」ボタンを押すと、次の画面が開きます。
(項目数が多いため、表示完了までに若干の時間を要します。)
 まず最初に開くのは、画面上部に3つあるタブのうち、中央のタブです。
(当アプリをインストールした後、最初に当画面を開いたときには、このタブから始まるようになっています。)
上下に隣り合う区画は、2色で交互に色分けされるようになっており、区画の境い目がわかりやすくなっています。
画面下段中央にある「セクション」チェックボックスにチェックを入れると
区画内を用途別などで区切る「セクション」も表示され、選択して指定できるようになります。
まず最初に開くのは、画面上部に3つあるタブのうち、中央のタブです。
(当アプリをインストールした後、最初に当画面を開いたときには、このタブから始まるようになっています。)
上下に隣り合う区画は、2色で交互に色分けされるようになっており、区画の境い目がわかりやすくなっています。
画面下段中央にある「セクション」チェックボックスにチェックを入れると
区画内を用途別などで区切る「セクション」も表示され、選択して指定できるようになります。
 「区画」「セクション」ともに、右側の「文字一覧」で現在表示できている部分が
オレンジ色の線で囲まれて、明るくなっています。
また、「区画」「セクション」ともに、各行をクリックすると
「文字一覧」の該当箇所が表示され、その先頭に位置付けられるようになっています。
「文字一覧」でマウスを移動させれば、マウスポインタが置かれた位置の、文字についての説明が
下段部分に表示され、その右にある黒地の拡大表示欄には、文字の字形が大きく表示されます。
「区画」「セクション」ともに、右側の「文字一覧」で現在表示できている部分が
オレンジ色の線で囲まれて、明るくなっています。
また、「区画」「セクション」ともに、各行をクリックすると
「文字一覧」の該当箇所が表示され、その先頭に位置付けられるようになっています。
「文字一覧」でマウスを移動させれば、マウスポインタが置かれた位置の、文字についての説明が
下段部分に表示され、その右にある黒地の拡大表示欄には、文字の字形が大きく表示されます。
 表示に最適なフォントは、区画ごとに別途指定でき、必要に応じて変更もできます。
(上の画像では、区画ごとに異なるフォントが適用されている様子がご確認いただけます。)
マウスポインタに連動する拡大表示欄は、区画ごとに指定されたフォントで表示されますので
中段のコンボボックスに表示されるフォント名も、区画ごとの指定フォントの名称が、常に表示されます。
「指定フォント」のチェックを外せば、フォント名のコンボボックスの操作が可能になりますので
「文字一覧」の全体に対して、コンボボックスで選択するひとつのフォントを適用して
そのフォントが区画の表示に適切に対応しているかどうかの確認などに使えます。
中段部分で「一覧表」から「リスト」へ切り替えれば、個々の文字に付けられた、文字名ごとのリストになります。
(切り替わった直後は、直前の先頭行の位置からの表示となります。次の画像は例示のために表示位置を動かしています。)
表示に最適なフォントは、区画ごとに別途指定でき、必要に応じて変更もできます。
(上の画像では、区画ごとに異なるフォントが適用されている様子がご確認いただけます。)
マウスポインタに連動する拡大表示欄は、区画ごとに指定されたフォントで表示されますので
中段のコンボボックスに表示されるフォント名も、区画ごとの指定フォントの名称が、常に表示されます。
「指定フォント」のチェックを外せば、フォント名のコンボボックスの操作が可能になりますので
「文字一覧」の全体に対して、コンボボックスで選択するひとつのフォントを適用して
そのフォントが区画の表示に適切に対応しているかどうかの確認などに使えます。
中段部分で「一覧表」から「リスト」へ切り替えれば、個々の文字に付けられた、文字名ごとのリストになります。
(切り替わった直後は、直前の先頭行の位置からの表示となります。次の画像は例示のために表示位置を動かしています。)
 なお、「区画」「セクション」「文字一覧」は、画面左上部分の Unicode「第○面」ごとに区切ってあります。
当初は「第0面」(基本多言語面) になっていますので、第1面以降を使う場合は切り替えてご利用ください。
また「第○面」にとらわれずに、Unicode全体を俯瞰的に見るには、後述の「全体索引」を利用すると便利です。
(コード順から区画名順に並べ替えたりもできるので、同じ系列の離れた区画などが探しやすくなります。)
(次の4枚の画像は、「リスト」から「一覧表」に戻したうえで
「第1面」(追加多言語面) と「第2面」(追加漢字面) と「第3面」(第三漢字面)
および「第15面」(私用面A) の、それぞれ先頭部分を表示しています。)
なお、「区画」「セクション」「文字一覧」は、画面左上部分の Unicode「第○面」ごとに区切ってあります。
当初は「第0面」(基本多言語面) になっていますので、第1面以降を使う場合は切り替えてご利用ください。
また「第○面」にとらわれずに、Unicode全体を俯瞰的に見るには、後述の「全体索引」を利用すると便利です。
(コード順から区画名順に並べ替えたりもできるので、同じ系列の離れた区画などが探しやすくなります。)
(次の4枚の画像は、「リスト」から「一覧表」に戻したうえで
「第1面」(追加多言語面) と「第2面」(追加漢字面) と「第3面」(第三漢字面)
および「第15面」(私用面A) の、それぞれ先頭部分を表示しています。)



 (私用面には Unicodeによる文字定義は存在しませんので、表示フォントの仕様に合わせた初期値を設定しています。)
(私用面には Unicodeによる文字定義は存在しませんので、表示フォントの仕様に合わせた初期値を設定しています。)
• Unicode文字一覧(オプション)
Unicode文字一覧のオプションは、拡大表示域の左端にある縦長のボタンから開く部分です。
(本項は当初「パスパ文字」で例示していましたが、より簡潔な「モンゴル文字」に変更しました。パスパ文字は「備考」欄へ移動しています。)
ここには「関連字等」「異体字セレクタ適用」「対応フォント一覧」の 3つのオプション表示が隠れています。
表示は縦長のボタンを押す度に切り替わっていき、最大で3つの切り替えを抜けると 元に戻ります。




「関連字等」や「異体字セレクタ適用」は、対象項目がなければ 画面切り替えのみで、内容は特に表示されません。
「対応フォント一覧」は、対象の文字そのものを表示可能と見られるフォントを列挙するものです。
「関連字等」は、基本的に「対象の文字に関連した文字」のことなので、対象の文字とは「別の文字」を指す情報になります。
「異体字セレクタ適用」は、対象の文字に「異体字セレクタ」を適用した「異体字表現」なので、「対象の文字」そのものを扱います。
これらの情報は、すべての文字にあるのではなく「特定の文字にだけある」ものなので、内容の有無は 対象の文字により異なります。
(「対応フォント一覧」に切り替わるのは、「関連字等」の下段右側(対応フォント一覧)にチェックを入れた場合のみです。)
「関連字等」には、左側下段の文字説明欄にも[→]付きで載っている Unicode 提供の文字説明データ、もしくは
ユーザーが記入した文字注釈(後述)などの、参照文字の情報が、隅付き括弧【】付きで 個別にリストアップされます。
この各行は、マウスのポインタを重ねれば その文字の情報とともに 拡大表示域にも その文字の字形が対応フォントで表示されるようになっており
その行をダブルクリックすれば「Unicode文字一覧表」での その文字の表示位置に 直接 ジャンプするようになっています。


(伝統的なモンゴル文字は電子的な扱いが難しく、現代モンゴル語の表記には 歴史的経緯から キリル文字 もしくは ラテン文字 が多用されます。)
(上図には Unicode のコード表 の説明と同じ関連字が掲載されており、ここでは キリル文字による代用字(音訳での翻字)U+0430 が示されています。)
「異体字セレクタ適用」は、Unicode にて あらかじめ用意された、当該文字の「別字形」(異体字)を表示するものです。
当アプリでは Unicode 側の定義データをもとに、当該文字のために用意された「異体字セレクタ」があれば個別に適用し
各行にマウスのポインタを重ねれば、当該文字の異体字形が 拡大表示域にも 表示されるようになっています。


(上図では当アプリを Windows Vista で使っていますが、モンゴル文字の異体字形については 指定フォントの仕様により 正しく表示できています。)
なお 異体字形は 当然ながら Windows 7 以降(10, 8.1, 7)でも 正しく表示されます。(下図は上から Windows 10, 8.1, 7 の場合です。)



「異体字セレクタ」(Variation Selector) は「字形選択子」ともいい、対象の文字に 異なる字形 が用意されている場合に
意図した字形で表現できるように、文字の直後に置く「見えない記号(符号)」のようなものです。
異体の字形は いくつか用意されていることが多く、複数ある選択肢の中から 選んだ字形を 特定するための符号 ということで
漢字表記では「字形選択[子]」になっているのが、選択肢の中からの特定に用いる「符号」であることをあらわしています。
Unicode 標準の異体字セレクタは U+FE00 ~ FE0F の 16種類です。これらは主として最多文字数の「漢字」以外の文字に使われることになっています。
異体字セレクタによる字形は、当アプリ内では 正しく表示できない場合でも、WEBブラウザを使えば 確認できる場合が多くなる傾向があります。
なお「モンゴル文字」区画内には 専用の異体字セレクタも3種類あります(Format Controls : U+180B ~ 180D : Mongolian Free Variation Selector)。
(ちなみに「漢字」の異体字表現に特化した異体字セレクタ (Ideographic-specific Variation Selector:IVS) は、U+E0100 ~ E01EF の 240種類です。)
「対応フォント一覧」は、文字通り、ご利用中のシステムにインストールされているフォントの中から
対象の文字を表示可能と見られるフォントをすべて列挙して、一覧にするものです。
(画面上で処理する場合には、各行にマウスのポインタを重ねれば そのフォントを使った字形が 拡大表示域に表示されるようになっています。)
前述のとおり「対応フォント一覧」に切り替わるのは、はじめの切り替え時に見えていた
「関連字等」の下段右側([対応フォント一覧]のチェックボックス)にチェックを入れておいた場合のみです。


(上図の拡大表示欄は、指定フォント [Noto Sans Mongolian] ではなく「エチオピア(ゲエズ)文字」用の [Abyssinica SIL] で表示されています。)
「対応フォント一覧」は、すべてのフォントで対象の文字の画像を作り、字形が得られたものをリストアップしていくという、手間のかかる処理です。
そのため、インストール済みフォントが多い場合には 字形のピックアップに時間がかかるようになるので、初期状態ではチェックを外してあります。
この切り替え画面の表示域は狭くなっていますし、異体字形もシステムや部品の仕様により正しく表示されない場合があります。
そのような場合には「関連字等」の下段にもあるボタンを押して「ブラウザで確認」したほうが、見やすく確認できて便利です。
| 「関連字等」の下段はボタンが小さくなっていますが
左側が「異体字セレクタ適用」、
右側が「対応フォント一覧」に対応した
「ブラウザで確認」用のボタンです。 |  | 左図の2つのボタンは、各機能に切り替えた画面の
最下段にある「ブラウザで確認」ボタンと同じ処理です。
特に右側の「対応フォント一覧」用のボタンでは
時間のかかる画面表示を省略できるので、効率的です。 |
 | |  |
(上図も Windows Vista で WEBブラウザには Firefox を使っており、左図では異体字形も正しく表示されています。)
(右図では対応フォントの数があまりに多いため、後半の字形リスト(対応フォント名一覧)が見えるよう、前半の字形一覧の途中をカットしています。)
ちなみに モンゴル文字は、続け書きによる字形変化を伴う縦書き専用の文字で、縦書きの行は左から右へと書き進む 左縦書き[⇊ ] で書かれます。 続け書きによる字形変化は、常用するインド系の文字(左横書き[⇉])やアラビア系の文字(右横書き[⇇])などではすでに実用化されている基盤技術です。 この技術を応用するため、Unicode の「モンゴル文字」は 字形が 90度 左へ 横倒しになっており、一旦横書きしたものを縦書きに直すことになっています。 (Unicode のモンゴル文字を使った具体的な表現につきましては、当方作成の別アプリ dNetFontViewer に関する こちらの記事 にて解説しています。)
また「漢字」の場合は、前述のように「異体字セレクタ」が 他の文字種で使われるものとは異なります。
(「漢字」の異体字表現に特化した異体字セレクタ (Ideographic-specific Variation Selector:IVS) は、U+E0100 ~ E01EF の 240種類です。) (さらに Unicode 標準の異体字セレクタ U+FE00 ~ FE0F の 16種類も、「CJK互換漢字」との互換性を示す際などに使われることがあります。) (漢字編:Unicode「漢字」を使ったオプションの例示を見るには、左のボタンをクリック)以下、漢字の場合も同様に例示しておきます。
(まずは Windows Vista の場合からです。)



(日本語環境での漢字など現行のメジャーな文字は対応フォント数も多いため、「対応フォント一覧」は画面上よりも「ブラウザで確認」をお薦めします。)
(上図も Windows Vista で WEBブラウザには Firefox を使っていますが、左図では漢字の異体字形も正しく表示されています。)
Windows 7 以降(10, 8.1, 7)の場合は システムレベルで対応するため「異体字セレクタ適用字形」が 画面内で確認できます。



(図は上から Windows 10, 8.1, 7 の場合です。マウスオーバーにより、拡大表示も U+6F22「漢」の異体字セレクタ適用字形で表示されています。)
(漢字の異体字形を表示するには「花園明朝A」「游ゴシック」「游明朝」「IPAmj明朝」などの「IVS 対応フォント」をご利用ください。)
Windows Vista, XP の場合は システム自体が公式には未対応のため、漢字の異体字セレクタは 当アプリでは無効となります。

(Windows Vista の当アプリでは 異体字セレクタが正しく適用されず 2文字分の幅となっており、拡大表示欄の表示も上にあがったようになっています。)
なお、同様の表示オプションは 後述の「漢字索引」にもあります。
• 全体索引
全体索引は、画面上部に3つあるタブのうち、左側のタブで開きます。
 前項「Unicode文字一覧」は、Unicodeの「第○面」ごとに区切られていますが
こちらの区画表では Unicodeの全体像を俯瞰的に捉えられるように「面」の指定は外しており
目的の文字種の「区画」や「セクション」が、探しやすくなるようにしています。
(セクションについては、ここでは「面-区画-セクション」のコード順で構成してあります。)
区画およびセクションの表は、前項「Unicode文字一覧」と同じく
当初は区画ごとに2色で交互に色分けされています。
区画やセクションの各行は、クリックするとお互いの該当箇所も表示されるようになっており
ダブルクリックすると、「Unicode文字一覧」の該当箇所へ、ジャンプするようにもなっています。
区画については、項目順に並べ替えもできますので
ダブルクリックのジャンプ機能と併せて、便利な索引としてご利用ください。
(セクションについては並べ替えても混乱が予想されるため、並べ替えには対応していません。)
区画の表は、当初は Unicodeのコード順に並んでいますが
表の上部の項目の見出し部分をクリックすると、その項目の内容順に並べ替えができます。
(同じ項目見出しでもう一度クリックすると、上下が逆順になります。)
たとえば、日本語の五十音順にしたい場合には「よみ」で並べ替え、
英語のアルファベット順にしたい場合には「英名」で並べ替えれば便利です。
ちなみに、左端の「順」をクリックすれば、当初のコード順に戻すことができます。
(「コード」では16進コードの桁数が不揃いなため、先頭部分以外は正しい順番になりません。)
なお、「全体索引」のタブから一旦離れて他のタブを使い、また「全体索引」に戻ってきた場合には
混乱を防ぐため、区画の並び順は自動的に、当初のコード順に戻るようになっています。
区画表の右側にある「フォント」欄には、「Unicode文字一覧」の「指定フォント」の名称が入っています。
ここは変更も可能で、各区画ごとに標準的に指定する、表示用フォントの名称を指定できます。
フォント名は、入力ミスがあると正しく反映されませんので、キーボードからの直接入力はできないようにしてあります。
変更する場合は、別項などから「コピー」して「貼り付け」の手順で変更してください。
(「Unicode文字一覧」のフォント名のコンボボックスの下側に小さく表示しているフォント名は
クリックするだけで簡単にコピーできるようになっています。
従来の「指定フォント」のチェックを外して、その区画で実際にフォントを適用してみて
表示の有効性が確認できたら、下側のフォント名をコピーして、こちらに貼り付ければ、設定完了です。)
前項「Unicode文字一覧」は、Unicodeの「第○面」ごとに区切られていますが
こちらの区画表では Unicodeの全体像を俯瞰的に捉えられるように「面」の指定は外しており
目的の文字種の「区画」や「セクション」が、探しやすくなるようにしています。
(セクションについては、ここでは「面-区画-セクション」のコード順で構成してあります。)
区画およびセクションの表は、前項「Unicode文字一覧」と同じく
当初は区画ごとに2色で交互に色分けされています。
区画やセクションの各行は、クリックするとお互いの該当箇所も表示されるようになっており
ダブルクリックすると、「Unicode文字一覧」の該当箇所へ、ジャンプするようにもなっています。
区画については、項目順に並べ替えもできますので
ダブルクリックのジャンプ機能と併せて、便利な索引としてご利用ください。
(セクションについては並べ替えても混乱が予想されるため、並べ替えには対応していません。)
区画の表は、当初は Unicodeのコード順に並んでいますが
表の上部の項目の見出し部分をクリックすると、その項目の内容順に並べ替えができます。
(同じ項目見出しでもう一度クリックすると、上下が逆順になります。)
たとえば、日本語の五十音順にしたい場合には「よみ」で並べ替え、
英語のアルファベット順にしたい場合には「英名」で並べ替えれば便利です。
ちなみに、左端の「順」をクリックすれば、当初のコード順に戻すことができます。
(「コード」では16進コードの桁数が不揃いなため、先頭部分以外は正しい順番になりません。)
なお、「全体索引」のタブから一旦離れて他のタブを使い、また「全体索引」に戻ってきた場合には
混乱を防ぐため、区画の並び順は自動的に、当初のコード順に戻るようになっています。
区画表の右側にある「フォント」欄には、「Unicode文字一覧」の「指定フォント」の名称が入っています。
ここは変更も可能で、各区画ごとに標準的に指定する、表示用フォントの名称を指定できます。
フォント名は、入力ミスがあると正しく反映されませんので、キーボードからの直接入力はできないようにしてあります。
変更する場合は、別項などから「コピー」して「貼り付け」の手順で変更してください。
(「Unicode文字一覧」のフォント名のコンボボックスの下側に小さく表示しているフォント名は
クリックするだけで簡単にコピーできるようになっています。
従来の「指定フォント」のチェックを外して、その区画で実際にフォントを適用してみて
表示の有効性が確認できたら、下側のフォント名をコピーして、こちらに貼り付ければ、設定完了です。)
• 全体索引(オプション)
画面右端で縦長に色が変わるボタンをクリックすると、全体索引のオプション設定を開くことができます。
(次の画像では、区画表が「英名」順に並んでおり、画面右側に全体索引のオプションが開いています。)
 ここでは、色分けの対象を「面」単位にするか「区画」単位にするかの切り替えと
区画表に表示する項目を増減するための、チェックボックスによる指定ができます。
(「コード」欄と「フォント」欄だけは、表示が消せないようになっています。)
用意されたすべての項目を表示した場合は、次のようになります。
ここでは、色分けの対象を「面」単位にするか「区画」単位にするかの切り替えと
区画表に表示する項目を増減するための、チェックボックスによる指定ができます。
(「コード」欄と「フォント」欄だけは、表示が消せないようになっています。)
用意されたすべての項目を表示した場合は、次のようになります。
 「枠数」は各区画の領域範囲に定義可能な文字数で、「実数」は実際に Unicodeに登録されている定義済み文字数です。
各区画には、いくつか未定義のコードポイントが残っている場合があるため、必ず[ 実数 ≦ 枠数 ]の関係になります。
「フォント」欄につきましては、上で説明したとおりですが
「初期フォント」欄は、別途、各区画の名称データのテキストファイルで記入した
各区画ごとの表示に有効な「対応フォント」の名称が、初期値として入るものです。
「フォント」欄は「Unicode文字一覧」の「指定フォント」になりますが
その元になっているのが「初期フォント」です。
「フォント」欄は、前述のように[一時的に変更]できるようにもしていますが
右クリックから[初期フォントに戻す]こともできるようになっています。
(初期フォントの変更は、各区画の名称データのテキストファイルで記入して変更します。後述)
「枠数」は各区画の領域範囲に定義可能な文字数で、「実数」は実際に Unicodeに登録されている定義済み文字数です。
各区画には、いくつか未定義のコードポイントが残っている場合があるため、必ず[ 実数 ≦ 枠数 ]の関係になります。
「フォント」欄につきましては、上で説明したとおりですが
「初期フォント」欄は、別途、各区画の名称データのテキストファイルで記入した
各区画ごとの表示に有効な「対応フォント」の名称が、初期値として入るものです。
「フォント」欄は「Unicode文字一覧」の「指定フォント」になりますが
その元になっているのが「初期フォント」です。
「フォント」欄は、前述のように[一時的に変更]できるようにもしていますが
右クリックから[初期フォントに戻す]こともできるようになっています。
(初期フォントの変更は、各区画の名称データのテキストファイルで記入して変更します。後述)
• 漢字索引
漢字索引は、画面上部に3つあるタブのうち、右側のタブで開きます。
当アプリのインストール後に、最初に漢字索引を選んだときには、日本語の「音訓索引」から始まるようになっています。
 Unicode の「漢字」には、すでに9万字を超える文字数が登録されており、目的の漢字を探すのも なかなか大変です。
Unicode の「漢字」には、すでに9万字を超える文字数が登録されており、目的の漢字を探すのも なかなか大変です。
| 区画名 | 開始 | 終了 | (うち末尾) | 最終追加 | 枠数 | 実数 | 実数小計 |
| CJK統合漢字 | U+4E00 | U+9FFF | U+9FFC | Unicode 13.0 | 20,992字 | 20,989字 | 92,844字 |
| CJK統合漢字拡張A | U+3400 | U+4DBF | U+4DBF | Unicode 13.0 | 6,592字 | 6,592字 |
| CJK統合漢字拡張B | U+20000 | U+2A6DF | U+2A6DD | Unicode 13.0 | 42,720字 | 42,718字 |
| CJK統合漢字拡張C | U+2A700 | U+2B73F | U+2B734 | Unicode 5.2 | 4,160字 | 4,149字 |
| CJK統合漢字拡張D | U+2B740 | U+2B81F | U+2B81D | Unicode 6.0 | 224字 | 222字 |
| CJK統合漢字拡張E | U+2B820 | U+2CEAF | U+2CEA1 | Unicode 8.0 | 5,776字 | 5,762字 |
| CJK統合漢字拡張F | U+2CEB0 | U+2EBEF | U+2EBE0 | Unicode 10.0 | 7,488字 | 7,473字 |
| CJK統合漢字拡張G | U+30000 | U+3134F | U+3134A | Unicode 13.0 | 4,944字 | 4,939字 |
| CJK互換漢字 | U+F900 | U+FAFF | U+FAD9 | Unicode 6.1 | 512字 | 472字 | 1,014字 |
| CJK互換漢字補助 | U+2F800 | U+2FA1F | U+2FA1D | Unicode 3.1 | 544字 | 542字 |
| (※[CJK統合漢字]と[CJK互換漢字] の初回登録は Unicode 1.01 です。区画内追加はこれらのほか拡張A,Bでもおこなわれています。) |
|  | | 当アプリ[漢字索引]画面の左上部分には、Unicodeで最大の9万字以上もの文字数を誇る「漢字」について
後述する8種類の検索方法(検字法)が用意してあり、お好みの方法を選べるようになっています。
(次に示したのは それぞれの検字法での代表的な検索パネルです。
画像やタイトルをクリックすると 各項目の説明へジャンプするようになっています。) |
上図のような画面左側の 検索パネル では、選んだ検索方法ごとに、検索対象の絞り込み条件を設定していきます。
(入力域を持たない [部首索引][総画索引][ハングル] の3種については、項目をひとつ選べば それで検索される ようになっています。)
設定した条件で検索をおこなうと、検索結果の漢字は 画面右側に表示されるようになっています。
画面右側の 検索結果の下段には、検索結果の表示方法の切替スイッチ(ラジオボタン)も備わっています。
検字法ごとの選択の初期値は、次のようになっています。
| 検索方法(検字法) | 検索結果の表示方法 |
| |
部首索引
総画索引
音訓索引
ローマ字
ハングル
注音符号
倉頡
四角号碼 |
傍画数
総画数
音訓
拼音
한글
注音
倉頡
四角 |
 ([部首索引]のみ [傍][総]) ([部首索引]のみ [傍][総])


 ([拼音]:ピンイン) ([拼音]:ピンイン)
 ([한글]:ハングル) ([한글]:ハングル)


 |
| [部首] | [総画] | [音訓] | [R.音] | [R.訓] | [拼音] | [官話] | [広東] | [唐代] | [越南] | [韓国] | [한글] | [注音] | [倉頡] | [四角] |
| 康熙
部首 | 傍 | 総 | 音訓
索引 | ラテン文字(ローマ字)表記 | ハン
グル | 注音
符号 | 倉頡 | 四角
号碼 |
• [拼音]は ローマ字で示した表記法が8種類もあるので、単に代表として選んだものです。必要に応じて切り替えてください。(上図および次表参照)
• [康熙部首]は 現代にも通ずる漢字字典の祖 [康熙字典](1716年)で定められた 214種類 の部首で、Unicode でも参照しているものです。
• [傍画数]は 用語としては一般的なものではありませんが、[総画数]から[部首の画数]を除いた、[旁](つくり)などの[残りの画数]を示すものです。
部首ごとに分類される一般の[漢和辞典]などでも広く用いられている分類法で、当アプリでは[部首索引]においてのみ利用可能です。
当アプリの [傍画数][総画数] には Unicode の 漢字データベース [Unihan] にてデータ化されたものを用いています。
• [音訓]は 音読みをカタカナ、訓読みをひらがな で表記してあり(外来語等の例外あり)、[R.音][R.訓]はそのローマ字表記です。
(Unihan ではローマ字だけが提供されていますが 間違いの箇所が多いため、独自に調べ直してローマ字と仮名文字のデータを作り直してあります。)
| 検索結果の表示方法 | 誠
(U+8AA0) | 漢
(U+6F22) | 路
(U+8DEF) |
| [部首] | 康熙214部首 | [言]部(#149:7画) | [水]部(#85:3画) | [足]部(#157:7画) |
| [総画] | 総画数(部首を含んだ画数) | 13画/14画 | 14画/13画 | 13画 |
| [傍画] | 傍画数(部首を除いた画数) | 6画/7画 | 11画/10画 | 6画 |
| [音訓] | 日本語音訓 | 音読み:カタカナ
訓読み:ひらがな | セイ ジョウ
まこと まことに | カン
から | ロ
じ みち |
| [R.音] | ラテン文字
(ローマ字)
表記 | 音読み ローマ字表記 | SEI JOU | KAN | RO |
| [R.訓] | 訓読み ローマ字表記 | MAKOTO MAKOTONI | KARA | JI MICHI |
| [拼音] | 漢語拼音(ピンイン,標準中国語) | chéng | hàn, tān | lù, luò |
| [官話] | 官話方言(普通話・台湾国語) | chéng | hàn | lù |
| [広東] | 広東語(粵語,香港周辺) | sing4 | hon3 | lou6 |
| [唐代] | 唐の時代の発音(漢詩,研究用) | *zhiɛng | *xɑ̀n | *lò |
| [越南] | ベトナム語(クォック・グー) | thành | hán | lộ |
| [韓国] | 朝鮮語(韓国語) ローマ字表記 | SENG | HAN | LO |
| [한글] | ハングル翻字 | 朝鮮語(韓国語) ハングル表記 | [성](U+C131:SEO-NG) | [한](U+D55C:HA-N) | [노](U+B178:NO), [로](U+B85C:RO) |
| [注音] | 注音符号(字母) | ㄔㄥˊ (t/6) | ㄏㄢˋ (c04) | ㄌㄨˋ (xj4) |
| [倉頡] | 倉頡輸入法(字根) | 卜口戈竹尸 (YRIHS) | 水廿中人 (ETLO) | 口一竹水口 (RMHER) |
| [四角] | 四角号碼(最大5桁までのアラビア数字) | 0365₀ | 3413₄ | 6716₄ |
• [拼音](ピンイン)は 現代中国における標準中国語の発音を示したローマ字表記[漢語拼音]のことです。[四声]と呼ばれる4声調は記号(分音符)で示されます。
• [官話]は 北京周辺で話される[官話方言][マンダリン]、現代中国の[普通話]、台湾(中華民国)の[(台湾)国語] のことです。ローマ字は拼音に近くなります。
(台湾で北京官話が話されるのは、北京にあった[中華民国]国民党政府が 中国共産党(人民解放軍)に追われ、南京経由で台北に遷都してきたためです。)
• [広東]は 日本では一般に[広東語]と呼ばれ 香港から中国[広東省]など広い地域で話される [粵語](えつご)のことです。9種類ある声調は数字で示されます。
• [唐代]は 中国の漢詩などを研究する西洋の学問[中国学]による[唐]の時代の発音のローマ字表記です。源流は日本語の[音読み]に保存された中古音など。
• [越南]は 戦後に漢字を全廃したベトナムで現在使われるローマ字表記[クォック・グー]による漢字の読み方です。複雑な発音は声調記号も重層的になります。
• [韓国]は 韓国語(朝鮮語)で漢字を読んだ際のローマ字表記で、[한글](ハングル)は 韓国語(朝鮮語)のハングルで漢字を表記し直したもの(ハングル翻字)です。
(韓国語(朝鮮語)もベトナム語も、もとは漢字表記の言語でした。中国や日本も含んだ[漢字文化圏]4カ国は頭文字で[CJKV]ともいい、他は非漢字です。)
• [注音]は 20世紀初頭に 古代の漢字の字形から採られた 漢字の読み方を示す[注音符号]のことで、中華民国[台湾]では初等教育で習得する基礎的な文字です。
• [倉頡]は パソコン等の漢字入力方式として 台湾で編み出され 英国領であった[香港]で主流となった[倉頡輸入法]で使われる 26種類の[字根]による表現です。
• [四角]は 漢字の四隅の形状を4桁の数字であらわし 似通った漢字の区別に1桁を加えて表現する [四角号碼] 検字法で使われる 最大5桁のアラビア数字です。



画面右側の 検索結果の漢字のセルは、ダブルクリックすると「Unicode文字一覧」の該当箇所へジャンプすることもできます。
検索結果右側の 検索結果の漢字用の表示フォントには、区画別に設定された「指定フォント」が適用されます。
(「CJK統合漢字」と「CJK統合漢字拡張n」など、区画によって指定フォントが異なる場合であっても
混在する検索結果にそれぞれのフォントが適用されて(セルごとに異なるフォントが混在した状態となって) 可能な限り適切に表示されます。)
検索結果左側の 検索対象となった項目を集約した部分は、クリックすれば 検索結果右側に項目分けされた漢字の先頭に位置づけられるようになっています。
(この部分の表示フォントには、設定画面で指定できる「説明用フォント」が用いられています。)
画面左下の「表示調整」は、画面左側の検索パネルの文字の大きさを、検索結果の文字と同じ大きさに揃えるものです。
チェックが入った状態では、特定の箇所について「見やすく拡大」していることをあらわしており
チェックを外すと、画面下段に見えている文字説明と同じ「説明用フォント」本来の大きさに(主観的には、やや小さく)なります。
その下の「漢字検索」は、チェックを外すと、漢字の検索機能を無効にするものです。(通常はチェックを入れておきます。)
ローマ字で用いるダイアクリティカルマーク付きのラテン文字や、ハングル、注音符号などの
日本語キーボードでは入力しづらい文字については、当アプリの検索ワードの入力欄を使って、文字列を作成すると便利です。
そのような「任意の文字列を作成するだけ」などの場合には、漢字の検索機能を不用意に使わない、という使い方ができます。
それでは 以下に、8種類の検索方法(検字法)を説明します。
掲載している画像は縮小表示していますが、クリックすると拡大して、前後に移動できます。
画像を拡大し、前後と見比べるなどしてご確認ください。
部首索引
漢字の部首をもとに、漢字を検索します。(「康熙部首」のほか、その他の部首字形と慣用読みも利用できます。)
| 部首索引の検索パネルは3種類あり、左上部分にあるボタンを押して切り替えできます。 |

(部首索引 部首(字形)) | 
(部首索引 康熙部首) | 
(部首索引 部首(読み)) |
現在の漢字の部首の分類は、[清]の時代の康熙帝による「康熙字典」で採られた214個の部首が基本になっています。
その「康熙部首」のほか、漢字文化圏では常識的な、4画の[水]を3画の[氵]であらわすなどの[部首字形]、および
日本語に特有の、[言部](げんぶ)を「ごんべん」、[酉]を「ひよみのとり」と呼ぶ、などの[慣用読み]も用意しました。 |
| |
| 「部首(字形)」の切り替えボタンの隣にある 数値の選択肢は、一度に表示する 列の数 を切り替えできるようにしたものです。 |

(部首(字形) 5列) | 
(部首(字形) 16列) | 部首字の大きさを小さめ(周囲と同じ)にするには
左下にある「表示調整」のチェックを外します。
*「表示調整」にチェックがあると、特定の範囲が
[検索結果の漢字]と同じ大きさになります。
チェックを外すと 周囲と同じ大きさに戻ります。
列数(1~30列)を 左図よりも増やしたい場合は
画面のサイズ(横幅)を変更するなどしてください。 |
| 「部首(字形)」では さらに 現代中国語で使われる[簡体字部首]の要否についても 上部チェックボックスで切り替えできます。 |
(部首(字形) 簡部含む) | 
(部首(字形) 簡部のみ) | 
(部首(字形) 簡部なし) |
| 「部首(字形)」および「康熙部首」では、部首字の画数を選択することにより、目的の選択肢を探しやすくできます。 |

(部首(字形) 8画) | 
(康熙部首 8画) | 「部首(字形)」には [水]→[⺡]、[心]→[⺖] など
一般によく使われる部首字形も含んでいるので
漢和辞典に準じた 探しやすい形式 になっています。
([心]/[⺖]など画数が違っても[同じ部首]です。)
「康熙部首」では 画数順に並んだ 部首の字形に
1~214 の番号が振られているために
派生的な部首字形が含まれないので
やや 専門的な探し方 になります。 |
| 「部首(読み)」では 慣用読みの頭1文字目を選んで、目的の選択肢を探しやすくできます。(↓[補助]は日本語で使われない部首字です。) |

(部首(読み) [い]) | 
(部首(読み) [の]) | 
(部首(読み) [補助]) |
| (慣用読みには 部首字の[音読み]と[訓読み]なども 追加してありますので、ほとんどの読み方を網羅した 探しやすい形式 になっているものと思われます。) |
| |
| 以下は [言]([言部](げんぶ)/ごんべん)を検索した場合を示しています。 |

(部首索引-1 部首(字形) 傍画数) | 
(部首索引-2 康熙部首 傍画数) | 
(部首索引-3 部首(読み) 傍画数) |
| 傍画数とは、総画数から部首の画数分を除いた[旁](つくり)などの、残りの画数です。部首を指定する部首索引のみにあります。 |
総画索引
漢字の総画数をもとに、漢字を検索します。(もっとも大雑把で、目的の漢字が探しにくい方式です。)

(総画索引) | Unicode 漢字データベース [Unihan] において提供されている、各漢字ごとの総画数を
左図で用意した選択肢の中から選びます。(総画索引の検索パネルは 左図の1種類だけです。)
(一部の漢字では 地域差などにより、画数データが複数になっている場合もあります。)
数字の色が薄い箇所は、その総画数を持つ漢字が無い、ということを示しています。
(検索自体はおこなわれますが、対象となる漢字が無いので、選択しても無意味だということです。)
選択肢の最後にある[すべて]は、総画数のみならず すべての積極的な絞り込み条件を外して
画面右側下段の選択肢(下記参照)で並べ直したい場合に向いています。 |
| |
一般的な漢和辞典などでは便利な場合もありますが、Unicodeでは全体の字数が多いため、目的の漢字は探しにくくなります。
さらに Unicodeでは日本語のほか中国語なども統合されており、画数の数え方も異なっている場合があるため注意が必要です。 |

(総画索引-1 総画 1画 総画数) | 
(総画索引-2 総画 12画 総画数) | 
(総画索引-3 総画 84画 総画数) |
(Unicode 13.0 より、最多画数の漢字は [84画] の U+3106C ([雲]と[龍]が3つずつある日本の国字、たいと,だいと,おとど) になりました。)
総画数では[12画]の字数が最も多いようです。(漢字検索の対象区画などを変更した場合は結果が違ってくることがあります。)
画面右側の下段の選択を切り替えると、検索結果の見方を切り替えることができます。(他の検索方法でも切替可能です。) |

(総画索引-4 総画 12画 [部首]) | 
(総画索引-5 同 [音訓](日本語)) | 
(総画索引-6 同 [拼音](標準中国語)) |

(総画索引-7 同 [越南](ベトナム語)) | 
(総画索引-8 同 [韓国](朝鮮語)) | 
(総画索引-9 同 [한글](ハングル)) |
| 検索結果の切替によって字数が違ってくるのは、その言語ごとに使われる漢字(読み方のある漢字)の数が異なるためです。 |
音訓索引
日本語の[音][訓]です。五十音図の並び順、および[ひらがな][カタカナ]、[区別する][区別しない]も切替できます。
| 音訓索引の検索パネルは 五十音の配置が3種類あり、[ひらがな][カタカナ]の別も含めて 右上部分のボタンで切り替えできます。 |

(音訓索引 ひらがな 横型右縦並び) | 
(音訓索引 ひらがな 横型左縦並び) | 
(音訓索引 ひらがな 縦型左横並び) |

(音訓索引 カタカナ 横型右縦並び) | 
(音訓索引 カタカナ 横型左縦並び) | 
(音訓索引 カタカナ 縦型左横並び) |
検索パネルで選択した仮名文字は 左上の検索ワード入力欄に順次追加され、[検索]ボタンを押せば 該当する漢字が表示されます。
([日本語入力環境]でご利用なら、入力欄に仮名文字列を直接入力したほうが 早い場合もあります。パネルは[非・日本語入力環境]の場合も想定しています。)
なお、右側に見えている [区別する][区別しない] の切り替えは [ひらがな][カタカナ] を区別するかどうかの話(後述)です。
これらのことから「音訓索引」に必要な機能の多くは、検索ワード入力欄を含む 最上段に集約されるように 配置してあります。 |
| |
多くの場合、日本に伝わった当時の中国語の発音が残ったものが[音読み]で、それにあたる日本語本来の読み方が[訓読み]です。
一般に[音読み]は[カタカナ]、[訓読み]は[ひらがな]で表記されます。(一部の外来語は 訓読みでもカタカナのものがあります。)
([音読み](字音)には本来、日本に伝わった時期により [呉音][漢音][唐音] 等の区別がありますが、現状では そこまでのデータ化は おこなわれていません。) |

(音訓索引-1 横型右縦並び) | 
(音訓索引-2 横型左縦並び) | 
(音訓索引-3 縦型左横並び) |
以上から当アプリでは、外来語など一部を除いて [音読み]≒[カタカナ]、[訓読み]≒[ひらがな] の図式が成り立つことになります。
[音読み]と[訓読み]を区別したい場合は、[区別する]を選んで、検索ワードの入力を[ひらがな][カタカナ]で分けて検索します。 |

(音訓索引-4 区別 カタカナ(音読み)) | 
(音訓索引-5 区別 ひらがな(訓読み)) | |
検索ワードは、通常は「検索」ボタンを押すか、項目を切り替えることで検索しますが、[入力後]から[逐次]に切り替えると
入力が1文字ずつ進行するごとに検索するようにもできます。(この違いは画像ではわかりにくいため説明画像はありません。)
なお 通常は、検索ワードが先頭部分に一致する[先頭]で検索しますが、完全一致の[全長]、部分一致の[部分]も利用可能です。 |

(音訓索引-6 [先頭] [なみ…]) | 
(音訓索引-7 [全長] [=なみ]) | 
(音訓索引-8 [部分] […なみ…]) |
| ※ Unicodeのデータ(Unihan)には、日本語の音訓に関しては間違いの箇所が多いため、独自に調べ直した訂正版にしています。 |
以上は、日本の 漢和辞典 などでも よく使われる、国内で主流の検字法です。
以下は、日本国内ではあまり使われない方法となります。
ローマ字
中国語や広東語のピンイン(拼音)、ベトナム語のクオック・グー(國語)、日本語音訓のローマ字などに対応します。
| ローマ字用の検索パネルは 3種類の配置を用意しており、右上側のボタンで切り替えできます。 |

(ローマ字 キーボード配列 小文字) | 
(ローマ字 拼音ほか用 小文字) | 
(ローマ字 ベトナム語用 小文字) |
[キーボード配列]は 汎用性が高いもので、[拼音ほか用]と[ベトナム語用]は それぞれ必要な 文字・記号だけに絞ったものです。
ラテン文字の [大文字][小文字] の区別は 検索では不問となっていますが、必要なら 左下のボタンで切り替えできます。 |

(ローマ字 キーボード配列 大文字) | 
(ローマ字 拼音ほか用 大文字) | 
(ローマ字 ベトナム語用 大文字) |
| 声調記号のダイアクリティカルマークは 合成済みの文字も使えますし、ラテン文字に続けて打てば 自動的に合成(変換)されます。 |

(ローマ字-1 キーボード配列) | 
(ローマ字-2 拼音ほか用) | 
(ローマ字-3 ベトナム語用) |
検索パネルで選択したローマ字は 左上の検索ワード入力欄に順次追加され、[検索]ボタンを押せば 該当する漢字が表示されます。
([簡体字中国語]や[ベトナム語]などの入力環境でご利用なら、入力欄にキーボードからラテン文字列を直接入力したほうが 早い場合もあります。) |
| |
画面右側の下段の選択を切り替えると、検索結果の見方を切り替えることができます。(他の検索方法でも切替可能です。)
日本語の音訓は、ローマ字においてはラテン文字だけのため[音]と[訓]とに分かれており、[R.音][R.訓]ごとに検索できます。 |

(ローマ字-4 キーボード配列 [R.音]) | 
(ローマ字-5 同 [R.訓](日本語)) | 日本語でも、検索結果がローマ字の場合は
仮名文字による[五十音順]ではなく
ラテン文字の[アルファベット順]に並びます。 |
※ Unicodeのデータ(Unihan)には、日本語の音訓に関しては間違いの箇所が多いため、独自に調べ直した訂正版にしています。
([音訓]には Unihan由来のデータだけでなく追加分を含む場合があるため、検索結果の文字数は一致しないことがあります。) |

(ローマ字-6 同 [拼音](標準中国語)) | 
(ローマ字-7 同 [官話](官話方言)) | 
(ローマ字-8 同 [広東](粵語方言)) |
標準中国語の普通話では、ローマ字の[漢語拼音]が主流で、ラテン文字による漢字入力方法[拼音输入法]も広く普及しています。
[官話]方言は 普通話の元になった北京周辺の北方地域の方言で、標準中国語とされる普通話とは やや異なるものです。
広東語(粵語)は、普通話(漢語拼音)の四声と異なり 最大9種類の声調、ローマ字の方式も[粤拼]といい、普通話とは異なります。 |

(ローマ字-9 同 [唐代](唐の時代)) | 
(ローマ字-10 同 [越南](ベトナム語)) | 
(ローマ字-11 同 [韓国](朝鮮語)) |
[唐代]は研究者向きで、実用的ではありません。(中国を研究する学問「中国学」で利用。日本語の音読みで保存された当時の中国語の中古音など)
ベトナム語は、現在はラテン文字にダイアクリティカルマークを多用する「クォック・グー」となっているので、その表記です。
朝鮮語(韓国語)は、現在では音節文字のハングルでの表記が主流です。その発音をローマ字で表記した場合の漢字となります。 |

(ローマ字-12 同 [音訓](日本語仮名)) | 
(ローマ字-13 同 [한글](ハングル)) | 
(ローマ字-14 同 [注音](注音符号)) |
[音訓](日本語仮名)や[한글](ハングル)など、検索結果がローマ字以外の場合は、ローマ字からの逆引き的な使い方になります。
台湾で使われる[注音](注音符号)も逆引きで、ローマ字の発音で 注音符号を使った表記を参照するなどの用途に利用できます。 |
ハングル
朝鮮語(韓国語)で使われていた漢字を、現代朝鮮語の発音(音節)を表現するハングルから検索できます。
| ハングル用の検索パネルは 3種類の配置を用意しており、最上段のボタンで切り替えできます。(字数は同じです) |

(ハングル 反切表) | 
(ハングル 韓国様式) | 
(ハングル 北朝鮮様式) |
| 検索パネルの文字を小さくして字数を多くし表示範囲を拡げるには、画面左下の[表示調整]のチェックを外します。 |

(ハングル 反切表 調整解除) | 
(ハングル 韓国 調整解除) | 
(ハングル 北朝鮮 調整解除) |
| (まだ見えていない部分はスクロールすれば表示できます。表示範囲を 上図よりも拡げたい場合は、画面のサイズ(縦幅・横幅)を変更するなどしてください。) |
ハングルは、朝鮮語の[初声子音-中声母音-終声子音]という一連の音節を1文字で表現します(終声子音は無い場合もあります)。
反切表のハングルは終声子音(パッチム)の選択により変化します。 |

(ハングル-1 가 (GA/KA)) | 
(ハングル-2 각 (GAK/KAK)) | 
(ハングル-3 감 (GAM/KAM)) |
画面右下の選択を切り替えると、検索結果の見方を切り替えることができます。(他の検索方法でも切替可能です。)
次の例では右下を[한글](ハングル)から[韓国](朝鮮語)へ切り替えており、該当する漢字の他の読み方も同時に参照しています。 |

(ハングル-4 가 (GA/KA) [韓国]) | 
(ハングル-5 간 (GAN/KAN) [韓国]) | 
(ハングル-6 온 (ON) [韓国]) |
| 朝鮮語でハングルを使わずに[読み方]から漢字を検索する場合は、前項[ローマ字]の画面右側下段で[韓国](朝鮮語)を選びます。 |
注音符号
台湾の初等教育で習得し、漢字の読み方をあらわす注音符号から、漢字を検索できます。
| 注音符号の検索パネルは 3種類の配置を用意しており、右上側のボタンで切り替えできます。 |

(注音符号 列配置) | 
(注音符号 キーボード配列) | 
(注音符号 説明表で指定) |
注音符号は、台湾では小学生以上なら「誰でも習った常識」であり、繁体字圏の漢字入力方式「注音輸入法」にも使われます。
[列配置]や[キーボード配列]は、現地で実際に習ったり使ったりした人向けです。慣れない人には[説明表で指定]がお薦めです。 |

(注音符号-1 列配置) | 
(注音符号-2 キーボード配列) | 
(注音符号-3 説明表で指定) |
検索パネルで選択した注音符号は 左上の検索ワード入力欄に順次追加され、[検索]ボタンを押せば 該当する漢字が表示されます。
([繁体字中国語](台湾式)の入力環境でご利用なら、入力欄にキーボードから注音符号を直接入力したほうが 早い場合もあります。) |
| 「字母」はラテン文字とも対応付けが可能なので、左下のボタンで切り替えできるようにしています。その際には入力欄内の文字列も変わるようになっています。 |

(注音符号 字母) | 
(注音符号 小文字) | 
(注音符号 大文字) |
倉頡
繁体字圏の台湾で考案され香港では主流となった漢字入力方式「倉頡輸入法」で、漢字を検索できます。
| 倉頡用の検索パネルは 3種類の配置を用意しており、右上側のボタンで切り替えできます。 |

(倉頡 列配置) | 
(倉頡 キーボード配列) | 
(倉頡 説明表で指定) |
漢字を創製したといわれる伝説上の人物「蒼頡」の名に因み、漢字を分類した「字根」を組み合わせて候補を絞り込む方式です。
[列配置]や[キーボード配列]は、現地で実際に習ったり使ったりした人向けです。慣れない人には[説明表で指定]がお薦めです。 |

(倉頡-1 列配置) | 
(倉頡-2 キーボード配列) | 
(倉頡-3 説明表で指定) |
検索パネルで選択した「字根」は 左上の検索ワード入力欄に順次追加され、[検索]ボタンを押せば 該当する漢字が表示されます。
([繁体字中国語](香港式)の入力環境でご利用の場合などは、入力欄にキーボードから「字根」またはラテン文字を直接入力したほうが 早い場合もあります。) |
| 「字根」はラテン文字とも対応付けが可能なので、左下のボタンで切り替えできるようにしています。その際には入力欄内の文字列も変わるようになっています。 |

(倉頡 字根) | 
(倉頡 小文字) | 
(倉頡 大文字) |
四角号碼
漢字の四隅の形状を0~9の番号で表現した4桁([附角]も加えると最大5桁)の数字で、漢字を検索できます。
| 四角号碼の検索パネルは 3種類の配置を用意しており、右上側のボタンで切り替えできます。 |

(四角号碼 列配置) | 
(四角号碼 テンキー配列) | 
(四角号碼 説明表で指定) |
専門性の高い一部の字典などに採用されている検字法で、あまり一般的ではありませんが、研究者などには重用される方式です。
左上-左下-右上-右下の順で、漢字の四隅の形状を捉えて数字で表現し、多いものは1桁の[附角]を追加して絞り込み易くします。
[列配置]と[テンキー配列]は、並び順が違うだけです。漢字を数字で表現するため、四角号碼では[説明表で指定]がお薦めです。 |

(四角号碼-1 列配置) | 
(四角号碼-2 テンキー配列) | 
(四角号碼-3 説明表で指定) |
検索パネルで選択した数字は 左上の検索ワード入力欄に順次追加され、[検索]ボタンを押せば 該当する漢字が表示されます。
(入力欄にキーボードやテンキーから アラビア数字を直接入力したほうが 早い場合が多いと思われます。四角号碼ではアラビア数字のみが有効です。) |
• 漢字索引(オプション)
漢字索引のオプションは、下段部分にある縦長のボタンから開きます。
漢字検索での拡大表示域の左端にある縦長ボタンは
「Unicode文字一覧」での拡大表示域と同様に切り替わるようになっています。



 拡大表示域が、最後の「対応フォント一覧」に切り替わるのは
「関連字等」の下段右側(対応フォント一覧)にチェックを入れた場合のみです。
画面の表示域は狭くなっていますし、異体字セレクタは当アプリ内では部品の仕様により正しく反映されませんので
「関連字等」の下段でボタンを押して「ブラウザで確認」したほうが、見やすく確認できて便利です。
拡大表示域が、最後の「対応フォント一覧」に切り替わるのは
「関連字等」の下段右側(対応フォント一覧)にチェックを入れた場合のみです。
画面の表示域は狭くなっていますし、異体字セレクタは当アプリ内では部品の仕様により正しく反映されませんので
「関連字等」の下段でボタンを押して「ブラウザで確認」したほうが、見やすく確認できて便利です。

 Windows 7 以降(10, 8.1, 7)の場合は システムレベルで対応するため「異体字セレクタ適用字形」が 画面内で確認できます。
Windows 7 以降(10, 8.1, 7)の場合は システムレベルで対応するため「異体字セレクタ適用字形」が 画面内で確認できます。



(図は上から Windows 10, 8.1, 7 の場合です。マウスオーバーにより、拡大表示も U+6F22「漢」の異体字セレクタ適用字形で表示されています。)
(漢字の異体字形を表示するには「花園明朝A」「游ゴシック」「游明朝」「IPAmj明朝」などの「IVS 対応フォント」をご利用ください。)
Windows Vista, XP の場合は システム自体が公式には未対応のため、漢字の異体字セレクタは 当アプリでは無効となります。

(Windows Vista の当アプリでは 異体字セレクタが正しく適用されず 2文字分の幅となっており、拡大表示欄の表示も上にあがったようになっています。)
さらに、漢字検索では、説明表示域の左右にも、縦長のオプションボタンがあります。
中央寄りの、説明表示域の右端にある縦長ボタンは、次のように開きます。



上部左側にある [△][▽] ボタンは、検索結果に表示する文字の大きさを調節できます。
その右にあるコンボボックスは、検索結果を表示する列の数です。
1~30までの具体的な列数と、40~100 については10列単位で、自由に変更できます。
その下の「漢字オプション」6項目は、漢字検索の設定を、チェックボックスで端的にまとめたものです。
(細かい設定は、説明表示域の左側にある縦長ボタンから開きます。)
漢字オプション:

• 日本語 チェックが入ると、データとして日本語の読み方を持つ漢字だけを、検索対象にします。
• 常用漢字 チェックが入ると、日本国内で使われる、現行の「常用漢字表」に載った漢字だけを、検索対象にします。
(常用漢字表に示される旧字体も対象となります。)
• 簡部含む 中国語の簡体字の部首を持つ漢字について、扱い方を選べます。
(簡体字かどうかは部首だけで決まるものではありません。)
このチェックボックスには、3通りの状態があります。
☑ 簡部含む 簡体字の部首に関しては無条件。検索結果には簡体字の部首を持つ漢字も含まれます。
■ 簡部のみ 簡体字の部首を持つ漢字だけを検索対象にします。
☐ 簡部なし 簡体字の部首を持たない漢字だけを検索対象にします。
• 字数 チェックが入ると、検索結果の左上部分(インデックス側の上部)に、検索結果の「のべ字数」を表示します。
(検索結果が複数の項目に分かれる場合、同じ漢字の重複分もカウントされます。)
• 適正化 この項目は、混乱を防ぐため、通常はチェックを入れたままにしておきます。
チェックが入っていれば、画面左上の「音訓索引」などの検索方法と
右下の「音訓」などの検索結果の表示方法とで
同じ方法を採る場合には、指定した検索キーに沿ったものにして、検索結果を適正化します。
(異なる方法を採る場合、あるいは適正化のチェックを外した場合には
指定した検索キーを持つ漢字であれば
別の読み方なども検索結果にリストアップされてしまうことになります。)
• 見出し チェックが入ると、検索結果の左側に、参照しやするするための、インデックスを表示します。
(インデックスをクリックすれば、下のほうにある項目にも辿り着きやすくなります。)
説明表示域の左端の縦長ボタンでは、オプション画面が2回切り替わるようになっています。
(設定対象は2種類ずつの計4種類あり、左端の縦長ボタンは3回目のクリックで元に戻ります。)



左端から開く設定対象の全項目は、初期設定では以下のようになっています。
(画像の項目数や件数等の数値は Unicode 13.0 時点のものです。)
(切替1:「検索対象」および「対象地域」)
 | |  |
(切替2:「対象区画」および「項内順序」)
「項内順序」とは、漢字検索結果の各項目内における、個々の漢字の登場順序のことです。
初期値では「対象区画の推奨順(1)」になっています。(区画は略号で記載)
「対象区画」の画像でお判りのように「CJK[互換]漢字」の系統は
混乱の無いよう、初期設定において、漢字検索の対象から外してあります。
このため、一般的な利用では、設定変更の必要は無いものと思われます。
特に対象を絞り込んだ上で検索したいなどの場合にご利用ください。
切替1の左側「検索対象」の [康熙]から[倉頡2]まで や 右側「対象地域」、および 切替2の右側「項内順序」の細目は
Unicodeの漢字データベース(Unihan)の情報をもとにしています。
詳しくは[
UAX #38 Unicode Han Database (Unihan)]をご参照ください。
なお、切替1の左側「検索対象」で線が引かれた下段部分 [追加分1,2,3](下図左)については
[音訓][ローマ字]にチェック欄がありますが、これらは「日本語としての読み方」のことを意味しています。
具体的には次の右図のように、設定画面域を切り替えると表示できる「■ 文字の読み方 ■」欄(後述)にある
[漢字かな][漢字ローマ字]ごとの設定用ファイルが対応しているので、対象の漢字でファイルを分けて指定する
[かな(音訓)]や[ローマ字]を入力しておくことで、検索対象をチェックで分けることが可能になります。
(検索対象を分けたほうがいいのは、人名に使われる漢字の読み方など、一般の読み方とは異なる特殊な読み方をする場合などが当てはまります。)
(入力書式以外は、設定用ファイルの使い方は自由です。ある漢字の[音訓]を入力したら[ローマ字]も入力しないといけない、などの決まりごとはありません。)
• 設定画面
画面上部の「設定」にチェックを入れると、画面下部が拡張して「設定画面」が表示されます。
 この右端にある縦長のボタンをクリックするか、画面上部の「検索」にもチェックを入れた場合は
画面下部は次のようになるので、後述の「検索」機能を同時に使うこともできます。
この右端にある縦長のボタンをクリックするか、画面上部の「検索」にもチェックを入れた場合は
画面下部は次のようになるので、後述の「検索」機能を同時に使うこともできます。
 (設計上こちらのほうが間隔が詰まって見やすくなるのでお薦めです。以下なるべく原寸大で説明を進めます。)
(設計上こちらのほうが間隔が詰まって見やすくなるのでお薦めです。以下なるべく原寸大で説明を進めます。)
 「説明用フォント」は、文字や区画などの説明表示域、および、区画やセクションなどを指定する選択画面などのフォント
(区画ごとに対象フォントを指定することで表示される「文字」以外のフォント)を選択できます。
「説明用フォント」は、文字や区画などの説明表示域、および、区画やセクションなどを指定する選択画面などのフォント
(区画ごとに対象フォントを指定することで表示される「文字」以外のフォント)を選択できます。
 コンボボックスに表示されているフォント名は、それぞれのフォントが実際に適用された表示となっています。
説明用フォントには、日本語環境なら「花園フォント」「和田研フォント」「IPAフォント」などの
対応文字数の多いものを選ぶとよいでしょう。(漢字の部首索引に使う部首字などが正しく表示できるもの)
コンボボックスの下に再表示されるフォント名は、クリックするだけで「コピー」されるようになっています。
なお、説明用フォントの文字の大きさは、右側の [△][▽] ボタンで調節できます。
「全体オプション」は、当アプリもしくは当画面の、全体的な動作についてのオプション指定です。
コンボボックスに表示されているフォント名は、それぞれのフォントが実際に適用された表示となっています。
説明用フォントには、日本語環境なら「花園フォント」「和田研フォント」「IPAフォント」などの
対応文字数の多いものを選ぶとよいでしょう。(漢字の部首索引に使う部首字などが正しく表示できるもの)
コンボボックスの下に再表示されるフォント名は、クリックするだけで「コピー」されるようになっています。
なお、説明用フォントの文字の大きさは、右側の [△][▽] ボタンで調節できます。
「全体オプション」は、当アプリもしくは当画面の、全体的な動作についてのオプション指定です。
 • 次回は[リセット]してはじめる
当アプリの利用で生じた各種設定の変更を、次回起動時にはすべてリセットして始めることができます。
(当アプリ付属の[TOOLs]から起動できる「リサイクラー(再生)」と同等の機能です)
• 毎回起動時には、当画面を優先して表示する
調査画面よりも、当画面での作業を優先したい場合に選択します。
調査画面で「Unicode文字一覧」ボタンを押して当画面を表示する手間を省略できます。
• 漢字には編集した文字名をつける(推奨)
Unicodeの文字名は、文字数では最多の「漢字」には付けられていないため
漢字の部首や読みなどの、特定の説明項目を適宜編集して、文字名の代用にします。
• 複数の説明は、縦につなぐ
説明項目が複数ある場合は「箇条書き」のように縦に繋げます。
• 別コード
チェックが入ると、Unicode以外の文字コードも、ヒントなどに明記します。
コードの種類は、隣のコンボボックスで1種類だけ選択できます。
• Wiki言語
文字の表示域で右クリックして選択できる、文字調査用の Wiktionary の対象言語(○言語版)を指定します。
• ヒント([標準],[小],[中],[大],[固定],[なし])
文字の表示域でマウスオーバーすると、文字の説明が表示される、ツールチップヒント等の大きさを選べます。
[固定]のみ、ツールチップではなく、別画面を開いて表示します。
[固定]表示の内容は、マウスでなぞって範囲を指定して、コピーすることもできます。
• 次回は[リセット]してはじめる
当アプリの利用で生じた各種設定の変更を、次回起動時にはすべてリセットして始めることができます。
(当アプリ付属の[TOOLs]から起動できる「リサイクラー(再生)」と同等の機能です)
• 毎回起動時には、当画面を優先して表示する
調査画面よりも、当画面での作業を優先したい場合に選択します。
調査画面で「Unicode文字一覧」ボタンを押して当画面を表示する手間を省略できます。
• 漢字には編集した文字名をつける(推奨)
Unicodeの文字名は、文字数では最多の「漢字」には付けられていないため
漢字の部首や読みなどの、特定の説明項目を適宜編集して、文字名の代用にします。
• 複数の説明は、縦につなぐ
説明項目が複数ある場合は「箇条書き」のように縦に繋げます。
• 別コード
チェックが入ると、Unicode以外の文字コードも、ヒントなどに明記します。
コードの種類は、隣のコンボボックスで1種類だけ選択できます。
• Wiki言語
文字の表示域で右クリックして選択できる、文字調査用の Wiktionary の対象言語(○言語版)を指定します。
• ヒント([標準],[小],[中],[大],[固定],[なし])
文字の表示域でマウスオーバーすると、文字の説明が表示される、ツールチップヒント等の大きさを選べます。
[固定]のみ、ツールチップではなく、別画面を開いて表示します。
[固定]表示の内容は、マウスでなぞって範囲を指定して、コピーすることもできます。
 「全体オプション」の右側には、「背景色」および、特別な機能を持ったボタン群が用意されています。
「全体オプション」の右側には、「背景色」および、特別な機能を持ったボタン群が用意されています。
 背景色 … 当画面の上部に3つある「全体索引」「Unicode文字一覧」「漢字索引」のタブごとに
背景の色を指定できます。さらに、動的な「ヒント」と「カーソル」の色も指定できます。
「ヒント」は、項目にマウスオーバーすると表示されるツールチップヒントの背景色、
「カーソル」は、表の中でマウスポインタ(矢印)が重なった行やセルの色です。
それぞれがボタンになっており、ボタンを押すと「色の設定」画面が開きます。
なお「初期色」ボタンを押せば、何度でも初期設定の色に戻すことができます。
推奨フォントDL … 当方作成のフリーソフト「推奨フォントのダウンローダ」がインストールされていれば
当該ソフトを起動して、当方推奨の各種フォントをダウンロードすることができます。
外字リンク … 当アプリ付属の「外字リンク」アプリを起動できます。
当アプリ付属の外字ファイルなどの、別途作成した外字ファイルと
インストール済みフォントとの間に「リンク」を設定し、外字が表示されるようにできます。
(この付属アプリの起動には管理者権限による承認が必要です。)
規定フォント … 各区画の「指定フォント」は、「全体索引」の区画ごとの各行で、フォント名を変更できますが
これらは、後述する「区画名称」内に記入できる、各区画ごとの対応フォント名が元になっています。
その「元のフォント名」に一括して戻したい場合には、このボタンを使います。
【再起動】 … 当アプリを単純に一旦終了し、再び起動します。
当アプリなど Windows系アプリの多くは、アプリの起動時に インストール済みフォントを認識します。
つまり当アプリの起動後に追加インストールされたフォントは、当アプリは認識できませんので
当アプリに現在のフォントのインストール状況を再認識させる場合などに、ご利用ください。
中段から下段にかけての左端には、設定項目を部分的に切り替える、縦長のボタンがあります。
背景色 … 当画面の上部に3つある「全体索引」「Unicode文字一覧」「漢字索引」のタブごとに
背景の色を指定できます。さらに、動的な「ヒント」と「カーソル」の色も指定できます。
「ヒント」は、項目にマウスオーバーすると表示されるツールチップヒントの背景色、
「カーソル」は、表の中でマウスポインタ(矢印)が重なった行やセルの色です。
それぞれがボタンになっており、ボタンを押すと「色の設定」画面が開きます。
なお「初期色」ボタンを押せば、何度でも初期設定の色に戻すことができます。
推奨フォントDL … 当方作成のフリーソフト「推奨フォントのダウンローダ」がインストールされていれば
当該ソフトを起動して、当方推奨の各種フォントをダウンロードすることができます。
外字リンク … 当アプリ付属の「外字リンク」アプリを起動できます。
当アプリ付属の外字ファイルなどの、別途作成した外字ファイルと
インストール済みフォントとの間に「リンク」を設定し、外字が表示されるようにできます。
(この付属アプリの起動には管理者権限による承認が必要です。)
規定フォント … 各区画の「指定フォント」は、「全体索引」の区画ごとの各行で、フォント名を変更できますが
これらは、後述する「区画名称」内に記入できる、各区画ごとの対応フォント名が元になっています。
その「元のフォント名」に一括して戻したい場合には、このボタンを使います。
【再起動】 … 当アプリを単純に一旦終了し、再び起動します。
当アプリなど Windows系アプリの多くは、アプリの起動時に インストール済みフォントを認識します。
つまり当アプリの起動後に追加インストールされたフォントは、当アプリは認識できませんので
当アプリに現在のフォントのインストール状況を再認識させる場合などに、ご利用ください。
中段から下段にかけての左端には、設定項目を部分的に切り替える、縦長のボタンがあります。

 「拡大表示」は、初期値では黒地になっている、文字の拡大表示域についての設定項目です。
(この設定は「Unicode文字一覧」と「漢字検索」の両方で共用されます。)
「拡大表示」は、初期値では黒地になっている、文字の拡大表示域についての設定項目です。
(この設定は「Unicode文字一覧」と「漢字検索」の両方で共用されます。)

 • 表示モード … 通常はテキストモードですが、チェックを入れると グラフィクスモード[GDI+]での表示となります。
[GDI+]では、フォント設計上のアセント・ディセント、文字幅などのガイドラインも表示します。
• 色反転 … チェックを入れると、拡大表示域の文字と下地の色を、白と黒とで反転します。
• 文字コード併記 … チェックが入っていると、拡大表示域の上部に、別途選択した形式の文字コードを併記します。
• 拡大倍率 … 対象の文字の拡大倍率を選択・変更できます。
• 拡大表示域のグラフィクスモード(GDI+)では、テキストモードの文字に重ねて表示する (下記「指定例」をご参照ください)
• 拡大表示域に、テキストレンダリングモード(GDI)の表示を青色で重ねる (下記「指定例」をご参照ください)
(指定例)
• 表示モード … 通常はテキストモードですが、チェックを入れると グラフィクスモード[GDI+]での表示となります。
[GDI+]では、フォント設計上のアセント・ディセント、文字幅などのガイドラインも表示します。
• 色反転 … チェックを入れると、拡大表示域の文字と下地の色を、白と黒とで反転します。
• 文字コード併記 … チェックが入っていると、拡大表示域の上部に、別途選択した形式の文字コードを併記します。
• 拡大倍率 … 対象の文字の拡大倍率を選択・変更できます。
• 拡大表示域のグラフィクスモード(GDI+)では、テキストモードの文字に重ねて表示する (下記「指定例」をご参照ください)
• 拡大表示域に、テキストレンダリングモード(GDI)の表示を青色で重ねる (下記「指定例」をご参照ください)
(指定例)

(色反転)

| 
(グラフィクスモード[GDI+])

|

(テキストモードに[GDI+]を重ねる)
 | 
(テキストレンダリングモード[GDI]を青色で重ねる)
 |
「操作モード」は、文字の表示域を使って、その文字を利用しやすくする場合に選択します。

• 表示のみ :表示だけをおこなう、通常のモードです。
• クリックでコピー:文字の表示域で各セルをクリックすると、その文字をコピーしますので、他の場所へ貼り付けできます。

• 選択欄へ入力 :調査画面の左上入力欄2行のうち、選択した側のキャレット位置へ、クリックした文字が入力されます。

• 外部入力モード :当アプリ以外の入力可能な外部アプリへ、クリックした文字を送って、仮想的な「入力」ができます。

(最初に入力対象となる外部アプリをクリックして、対象を指定する操作が必要です。)

さらに「外部入力モード」では、特に日本語変換などにおいて、当アプリの文字の表示域から外部アプリへ文字を送るだけでは
操作上の機能が不足して不便な場合があるので、これを補うためのキーも用意しています。
• IME :日本語環境の場合は日本語変換モードに(他国語環境の場合はその言語版のIMEに)切り替えができます。
• 無変換 :キーボードの「無変換」と同じです。IMEで入力した状況を、変換せずにそのまま確定させます。
• 変換 :キーボードの「変換」(スペースキー)と同じです。IMEで入力した状況をもとに、変換候補を表示します。
• Ret :キーボードの「リターンキー」と同じです。IMEの変換候補の表示中なら、選択中の候補で確定させます。
• BS :キーボードの「バックスペース」(デリートキー)と同じです。カーソル位置の直前の1文字を削除します。
中央部分(設定画面の右側部分)は、画面が3回切り替わるようになっています。
(縦長ボタンは4回目のクリックで元に戻ります。)




この中央部分は、それぞれ最上部の項目が「基本項目」「基底名称等」「基底注釈」「字形選択肢」の4画面に分かれており
いずれも、当アプリ「Unicode文字一覧」で表示される、区画・セクション・文字といった項目についての
すべての説明(それぞれの「名称」および追加的な「注釈」)を設定している、根幹部分にあたります。




当アプリでは、文字や区画の名称などの基本的なデータは、Unicodeのデータをもとに
すべてテキストファイルの形式にしており、起動時に読み込んで、必要に応じて表示されるようになっています。
このテキストファイルは、必要がなければ 不用意に変更すべきではありませんが
必要な場合には、適切に変更してやることで、説明の変更や追加もできるようになっています。
(たとえば、日本語の訳し方を変更したいなどの場合は、自由に変更できるということです。)
テキストファイルは、基本的に「メモ帳」で開きます。
タブ区切り形式の場合は、表計算アプリ等を適切に併用すれば、編集しやすくなります。
保存用の文字コードには[UTF-8]を指定してあります。
[中央部切替1] 「基本項目」
すべての項目はチェックボックスになっていますので、ここでは選択のみが可能です。
上段側では「面」および「区画」「セクション」「文字」ごとに「英」「日」「入替」のチェックがあります。
Unicodeから提供される基本データは、当アプリ用には英語版を元にしていますが(フランス語版は廃止の模様)
当アプリのデータには、最新の英文に、当方による和訳を付けている部分もありますので、その扱いを選べます。
初期値ではすべてチェックが入っています。
これは、それぞれ「英語」と「日本語」の名称データを、ともに有効にしており
英語と日本語の、データで記入されている順序を「入れ替えて表示」していることを示しています。
さらに「面」を除いた「区画」「セクション」「文字」については「標準説明」の「英」「日」もあります。
標準説明というのは、Unicodeのコード表のpdf 内に書かれた、それぞれに固有の説明文のことです。
前提となる説明で、重要度が高いため、これにも当方の和訳をつけており、その要/不要を選択できます。
下段側では「文字」のレベルについて、名称や標準説明を除いた Unicodeの関連データ項目を
文字説明の一環として添付しています。
左側には、「非漢字」(漢字以外)についての項目が列挙されており
右側には、文字数で Unicode最多の「漢字」についての項目が列挙されています。
「非漢字」では、多くの場合、Unicode標準の「文字名」が、最良の説明となります。
そのためか関連データの項目数は少なくなっています。(異体字セレクタへの対応は別途)
「漢字」では、Unicode標準の「文字名」がなく、特に項目数も多いため、初期値では
専門性の高い項目については表示対象から除外し、選択数を抑えるように指定してあります。
[中央部切替2] 「基底名称等」 「名称(変更・追加)」 「外字」
• 基底名称等 … [区画][セクション][文字][漢字][追加文字]
Unicodeベースの、当アプリで最も基本となるデータ群です。
[区画][セクション][文字]には、元になった Unicodeの英文があり、それに当方で和訳を付けています。
[漢字][追加文字]には、Unicodeの英文が無いので、当方で別途まとめたり作成したデータです。
不用意な変更を避けるため、各データは[ダブルクリック]しないと開かないようになっています。
• [区画] ……… Unicodeでいうところの[Blocks]にあたるデータです。
• [セクション]… Unicodeのコード表pdf に見られる、[Block]内を区切る「節」です。
• [文字] ……… Unicodeの個々の文字や記号のデータです。(漢字とハングルを除く)
• [漢字] ……… Unicodeの漢字データ(Unihan)を、当アプリ向けに編集してまとめたものです。
• [追加文字] … Unicode標準の指針に従い、当方で作成したハングルのデータが入っています。
• 名称(変更・追加) … (〈 [区画][セクション][文字] 〉×3)×2
前項「基底名称等」の表示内容を、変更したり、追加したりするための、任意のデータを記入できます。
たとえば「外字」を登録できる「私用領域」区画を有効活用する場合は
いくつかの任意の名称を持つ区画に分けたり、個々の外字の文字名を追加したりしておき
フォントの選択状況に応じて、登録内容を切り替えて使う、などの主体的な利用が可能になります。
それぞれ[区画][セクション][文字]のボタンがあり、クリックすれば、それぞれのテキストファイルが開きます。
上段側の[名称1][名称2][名称3]では、チェックボックスの ON/OFF で、各ファイルの有効/無効を切替できます。
下段側の[切替名称1][切替名称2][切替名称3]では、ラジオボタンで、有効にする組を選択します。
「すべて」のボタンは、9つのファイルを、お使いの画面の大きさで分割して、画面いっぱいに表示します。
記入要領は、各ファイルの中味に書かれています。
上段側の初期値では、すべてにチェックが入っており
下段側のラジオボタンは[切替名称1]の組が選択されていますが
ファイルの中味は、特に有効なデータが入っていないファイルもあります。
[区画]については、英名、和名の次に、フォント名を記入できます。
これは、各区画の「指定フォント」のもとになる「基底フォント」となります。
(この初期値は、[名称1]の[区画]に入っています。)
• 外字 … 「設定を優先」のチェックボックス
前項の説明にあるように、外字を扱う「私用領域」を、複数の任意区画に分けた場合も
フォント名は任意区画ごとに設定できますので、その設定を優先する場合に、チェックを入れておきます。
(チェックを外すと、外字を扱う「私用領域」は、単一区画として扱いますので、単一のフォントとなるため
複数のフォントとリンクさせた外字ファイルを用いるなどの、用途の多様性が制限されることになります。)
[中央部切替3] 「基底注釈」 「注釈(追記)」

• 基底注釈 … [区画][セクション][文字]
Unicodeベースの、注釈データ群です。
Unicodeのコード表pdf にある注釈で、必要な場合のみ書かれ、可能な場合は和訳を付けています。
不用意な変更を避けるため、各データは[ダブルクリック]しないと開かないようになっています。
• [区画] ……… Unicodeのコード表pdf の、書かれる場合は先頭に書かれる注釈です。
• [セクション]… Unicodeのコード表pdf の、[Block]内を区切る「節」に対する注釈です。
• [文字] ……… Unicodeの個々の文字や記号に対する注釈です。(数が多いため和訳は未着手)
• 注釈(追記) … (〈 [区画][セクション][文字] 〉×3)×2
前項「基底注釈」の内容に「追加」する形で、任意のデータを記入できます。
それぞれ[区画][セクション][文字]のボタンがあり、クリックすれば、それぞれのテキストファイルが開きます。
上段側の[注釈1][注釈2][注釈3]では、チェックボックスの ON/OFF で、各ファイルの有効/無効を切替できます。
下段側の[切替注釈1][切替注釈2][切替注釈3]では、ラジオボタンで、有効にする組を選択します。
「すべて」のボタンは、9つのファイルを、お使いの画面の大きさで分割して、画面いっぱいに表示します。
記入要領は、各ファイルの中味に書かれています。
上段側の初期値では[注釈2]のみにチェックが入っており
下段側のラジオボタンは[切替注釈1]の組が選択されていますが
ファイルの中味は、特に有効なデータが入っていないファイルもあります。
[中央部切替4] 「字形選択肢」 「文字の読み方」 「漢字索引インデックス」
• 字形選択肢 … [非漢字][漢字]
Unicodeの定義による「字形選択肢」(異体字セレクタ)の適用データです。
不用意な変更を避けるため、各データは[ダブルクリック]しないと開かないようになっています。
標準字形とは異なる「異体字形」が別途定義されている文字については、対応フォントを併用すれば
異体字セレクタを文字の直後に適用することで、意図した字形を選択的に表示させることができます。
なお[漢字]は「CJK
統合漢字」系のみ、[非漢字]には「CJK
互換漢字」系が含まれます。
• 文字の読み方 … ( [非漢字][漢字かな][漢字ローマ字] )×3
[非漢字][漢字かな][漢字ローマ字]のボタンが3つずつあり、クリックすれば、各テキストファイルが開きます。
これらはそれぞれ、チェックボックスの ON/OFF で、各ファイルの有効/無効を切替できます。
「すべて」のボタンは、9つのファイルを、お使いの画面の大きさで分割して、画面いっぱいに表示します。
英字の [A] は「エー」か「エイ」だと思っていたら「アイ」「アー」「ア」などの読み方があります。
円周率 [π] の「パイ」も実は英語読みで、現代ギリシアでは「ピ」、古代ギリシアでは「ペー」だそうです。
上二点 [¨] は「ダイエレシス」とか「トレマ」とか「ウムラウト」とも呼ばれます。
こういった「読み方」は「注釈」にしてもいいのですが、まとめて書いたほうがわかりやすいので
読み方だけを、注釈とは別のファイルに分けたものです。
漢字の日本語読みについては、Unicodeによるローマ字データをもとにした「Unihan音訓」がありますが
当方で修正したものであり、修正する前は信頼性に欠ける部分が大きくなっていました。
そのため、これを補完するデータとして、当方にて別途用意したものです。
あまり一般的ではない、人名用の読み方などで拡張する場合にも適していると思われます。
漢字のローマ字表記は、日本語ではほとんど利用されませんが、中国語では漢語拼音(ピンイン)として
近年は特に漢字入力の方式などで、日常的に利用されています。さらに Unicodeのローマ字Unihanデータには
標準中国語(普通話)などのデータがありますが、中国語の「七大方言」レベルでは、未整備の部分があります。
初期値では、別途インターネットで公開されているデータをもとに
「呉語」「粤語(広東語)」「香港拼音」のローマ字データを追加しています。
• 漢字索引インデックス … 9種類
当画面上部の3番目のタブ「漢字索引」で、索引用に設けている項目の、基礎データです。
漢字索引の形式はそれぞれ異なるため、データの区切り方などの形式もまちまちです。
不用意な変更を避けるため、各データは[ダブルクリック]しないと開かないようになっています。
設定画面の項目は以上です。設定画面を閉じて検索画面だけにする場合は
次の画像のように、設定画面の範囲の右端にある縦長のボタンをクリックします。

• 検索画面
画面上部の「検索」チェックボックスのみにチェックを入れるか、画面下部が閉じた状態で
画面下部にある横長のボタンをクリックすると、画面下部が拡張して「検索画面」が開きます。
 左上には、検索ワードの入力欄があり、カーソルが点滅しています。
下側の3つの領域には、検索結果の「区画」「セクション」「文字」の情報が表示されるようになっています。
検索画面ですから「検索」ボタンもありますが、主要な機能はリターンキーでも動作します。
ここではためしに、検索ワードの入力域に「ヒエログリフ」と入力してみます。
左上には、検索ワードの入力欄があり、カーソルが点滅しています。
下側の3つの領域には、検索結果の「区画」「セクション」「文字」の情報が表示されるようになっています。
検索画面ですから「検索」ボタンもありますが、主要な機能はリターンキーでも動作します。
ここではためしに、検索ワードの入力域に「ヒエログリフ」と入力してみます。
 まだ検索ボタンは押していませんが、入力の進行中にも、[ヒ][エ][ロ][グ][リ][フ]の各文字に対する
「区画」「セクション」「文字」についての情報が、徐々に追加表示されていきます。
(日本語IMEがONの場合は、徐々にではなく一括入力されます)
これは「検索」した結果ではなく、入力された文字列を「調査」した結果に過ぎません。
この機能は、前述の「調査画面」の左上に2つある入力域で、任意の文字列を入力した場合と、基本的に同様です。
調査は、入力と並行して、自動的におこなわれます。
(ただしここでは、個別の行として表示された区画やセクションなどの情報でも
マウスのポインタを重ねれば、そのコードポイントについての名称や説明が表示され
拡大表示域にも指定済みのフォントで字形が表示されるようになっています。さらに
各行でダブルクリックすれば、「Unicode文字一覧」の該当セルへ、ジャンプすることもできます。)
ここでは「検索」したいので、「検索」ボタンを押して、実際に「検索」してみます。(リターンキーでもかまいません)
まだ検索ボタンは押していませんが、入力の進行中にも、[ヒ][エ][ロ][グ][リ][フ]の各文字に対する
「区画」「セクション」「文字」についての情報が、徐々に追加表示されていきます。
(日本語IMEがONの場合は、徐々にではなく一括入力されます)
これは「検索」した結果ではなく、入力された文字列を「調査」した結果に過ぎません。
この機能は、前述の「調査画面」の左上に2つある入力域で、任意の文字列を入力した場合と、基本的に同様です。
調査は、入力と並行して、自動的におこなわれます。
(ただしここでは、個別の行として表示された区画やセクションなどの情報でも
マウスのポインタを重ねれば、そのコードポイントについての名称や説明が表示され
拡大表示域にも指定済みのフォントで字形が表示されるようになっています。さらに
各行でダブルクリックすれば、「Unicode文字一覧」の該当セルへ、ジャンプすることもできます。)
ここでは「検索」したいので、「検索」ボタンを押して、実際に「検索」してみます。(リターンキーでもかまいません)
 検索すると、「ヒエログリフ」の語を持つ「区画」と「文字」が、一覧表示されました。
「区画」の欄では「エジプト・ヒエログリフ」と「アナトリア・ヒエログリフ」の2種類があることがわかりますね。
「文字」の欄には「エジプト・ヒエログリフ」ばかりが見えていますが
下へスクロールすれば「アナトリア・ヒエログリフ」の文字情報も見えることでしょう。
(「セクション」には「ヒエログリフ」の語に該当するものが無かったようです。)
やはり「検索」というのは、こういうことでないといけません。
上の画像では、文字の欄にマウスのポインタを重ねており、その文字の名称や説明と
その文字が属する区画に指定されたフォントで、字形が拡大表示されているのがわかります。
なお、「調査」ボタンを押せば、検索結果を廃して、文字列を入力した直後の「調査結果」の表示に戻すこともできます。
さて「検索」の機能について考えてみますと
区画や文字などの「名称」だけでなく、関連情報の「注釈」についても検索範囲を拡げたい場合があります。
あるいは、複数の検索ワードを使って「絞り込み」したい場合なども考えられます。
検索ワードの入力欄と検索ボタンとの間には、細い縦型のボタンが2つ並んでおり
検索ワードや検索機能についてのオプションを表示できるようになっています。
左側の縦型ボタンは、検索ワードの文字列の加工をおこなうオプションです。
検索ワードの入力欄を縮めて、左側へ向かって開きます。(おもにラテン文字に対して有効)
検索すると、「ヒエログリフ」の語を持つ「区画」と「文字」が、一覧表示されました。
「区画」の欄では「エジプト・ヒエログリフ」と「アナトリア・ヒエログリフ」の2種類があることがわかりますね。
「文字」の欄には「エジプト・ヒエログリフ」ばかりが見えていますが
下へスクロールすれば「アナトリア・ヒエログリフ」の文字情報も見えることでしょう。
(「セクション」には「ヒエログリフ」の語に該当するものが無かったようです。)
やはり「検索」というのは、こういうことでないといけません。
上の画像では、文字の欄にマウスのポインタを重ねており、その文字の名称や説明と
その文字が属する区画に指定されたフォントで、字形が拡大表示されているのがわかります。
なお、「調査」ボタンを押せば、検索結果を廃して、文字列を入力した直後の「調査結果」の表示に戻すこともできます。
さて「検索」の機能について考えてみますと
区画や文字などの「名称」だけでなく、関連情報の「注釈」についても検索範囲を拡げたい場合があります。
あるいは、複数の検索ワードを使って「絞り込み」したい場合なども考えられます。
検索ワードの入力欄と検索ボタンとの間には、細い縦型のボタンが2つ並んでおり
検索ワードや検索機能についてのオプションを表示できるようになっています。
左側の縦型ボタンは、検索ワードの文字列の加工をおこなうオプションです。
検索ワードの入力欄を縮めて、左側へ向かって開きます。(おもにラテン文字に対して有効)


• UPPER
• Capital
• lower | … 文字列をすべて大文字にします。
… 文字列の先頭1文字だけを大文字とし、残りは小文字にします。
… 文字列をすべて小文字にします。 |
右側の縦型ボタンには、検索機能のオプションが格納されています。
検索ボタンなど3つのボタンの表示を縮めて、右側へ向かって開きます。


チェックボックス(個別に有効/無効の選択。検索ワードに対する指定。初期値はともにチェックなし。)
• 合致 … 大文字/小文字の違いを含めて「完全に合致」するものを対象にする
• かつ … 複数の項目が入力されている場合に「AND検索」にして条件を絞り込む
ラジオボタン(複数の項目からひとつを選択。検索対象の指定。初期値は[説明]を選択。)
• コード … Unicodeの16進コード([U+]は除く)を検索対象にします。
• 文字 … 「文字そのもの」を検索対象にします。([調査]機能が働くため、あまり意味がありません)
• 説明 … 区画や文字などの「名称」、また、漢字などの場合は文字名の代わりの「説明」を、検索対象にします。
• 汎用 … 区画や文字などの「名称」に「コード」「注釈」も含めた、すべての情報を検索対象にします。
• 10進 … Unicodeの10進コード(アラビア数字のみ)を検索対象にします。
これらのオプションが必要になる場面は、そう多くはないかも知れませんが、必要が生じたときには便利かも知れません。
ここでは、使えることを知っておけばいいので、ご利用時には機能を組み合わせるなど、工夫してお使いください。
最後に、検索画面の両脇にある、縦長のボタンについても説明しておきます。
検索画面の左側には前述の「設定」画面、右側には「履歴/登録」画面があります。
検索画面は、画面上部の「設定」チェックボックスにもチェックを入れるか
左側にある縦長のボタンをクリックして、設定画面と一緒に使うこともできます。
あるいは、検索画面の右側にある縦長のボタンをクリックするか
「検索」タイトル右端にある「履歴/登録」のチェックボックスにチェックを入れると
検索画面の右半分を使って、「履歴編集」と「コレクション登録」画面が同時に開きます。

•「履歴」とは、「Unicode文字一覧」で、個々の文字のセルをクリックした「訪問履歴」のようなものです。
クリックした順に、新しいものが上の行として積み重なっていく仕組みになっており
「履歴」画面の左上部や「Unicode文字一覧」の下段側にある[◀][▶]ボタンで、前後に進むための情報になります。
履歴の順序は、マウス操作の「ドラッグ&ドロップ」で、自由に入れ替えることも可能です。
•「コレクション」とは、よく使う文字などを登録しておき、必要な場面で呼び出しやすくするものです。
この機能は、WEBブラウザでいう「お気に入り」のようなものです。
「Unicode文字一覧」または「漢字索引」の検索結果からは、セルを右クリックすると登録できます。
また、コレクション内を分類する「見出し」として「タグ」を挿入することもできます。(画像の[●]の行)
こちらも「ドラッグ&ドロップ」に対応し、順序を入れ替えたり、「履歴」から登録することも可能です。
どちらも、マウスのポインタを重ねれば、その文字の情報が表示されますし
ダブルクリックすれば、「Unicode文字一覧」の、その文字の箇所へ、ジャンプします。
説明は以上です。最後までご覧いただき、ありがとうございました。
 インストーラ [ UniCharFinder_Install.exe ] を zip圧縮形式 で ダウンロード
インストーラ [ UniCharFinder_Install.exe ] を zip圧縮形式 で ダウンロード
← 概要へ戻る 
Unicode文字の調査用ソフト")

Unicode文字の調査用ソフト")











































